并非所有amd显卡都需要这个第三方的ollama,比较新的显卡官方自动支持
查看支持情况 System requirements (Windows) — HIP SDK installation (Windows)
此教程仅测试过780m(1103)集显,其他设备支持如下
By GPU Arches (Alphabetical Order)
gfx1010:xnack-; gfx1011:xnack-; gfx1012:xnack- :
rocm.gfx1010-xnack-gfx1011-xnack-gfx1012-xnack-.for.hip.sdk.6.2.4.7z
gfx1010; gfx1012 (no xnack-) :
rocm.gfx1010-gfx1012-for.hip.sdk.6.2.4.7z
gfx1031:
rocm.gfx1031.for.hip.sdk.6.2.4.littlewu.s.logic.7z build with little wu's tensile logic
gfx1032:
rocm.gfx1032.for.hip.sdk.6.2.4.navi21.logic.7z
gfx1034; gfx1035; gfx1036:
rocm.gfx1034-gfx1035-gfx1036.for.hip.sdk.6.2.4.7z
gfx1103
rocm gfx1103 AMD 780M phoenix V5.0 for hip sdk 6.2.4.7z
gfx1150
rocm.gfx1150.for.hip.skd.6.2.4.7z
gfx1151
rocm.gfx1151.for.hip.skd.6.2.4.7z
gfx1200
rocm.gfx1200.for.hip.skd.6.2.4.7z
gfx1201(AMD Radeon RX 9070 XT; AMD Radeon RX 9070)
rocm.gfx1201.for.hip.skd.6.2.4-no-optimized.7z
If hipsdk cannot load the rocmblis ,try change the amdhip64_6.dll in rocm/bin from C:\Windows\System32
此教程编写时,版本为0.6.6
也可以用exe.但是后续由于要手动操作,所以还是推荐用压缩包,方便手动解压
这这个版本是amd hip sdk 6.2.4
当前是6.2.4 这个应该根据 ollama的要求不同,使用不同的版本
- 当前教程因为设备是780m(1103),所以使用的是
rocm.gfx1103.AMD.780M.phoenix.V5.0.for.hip.sdk.6.2.4.7z
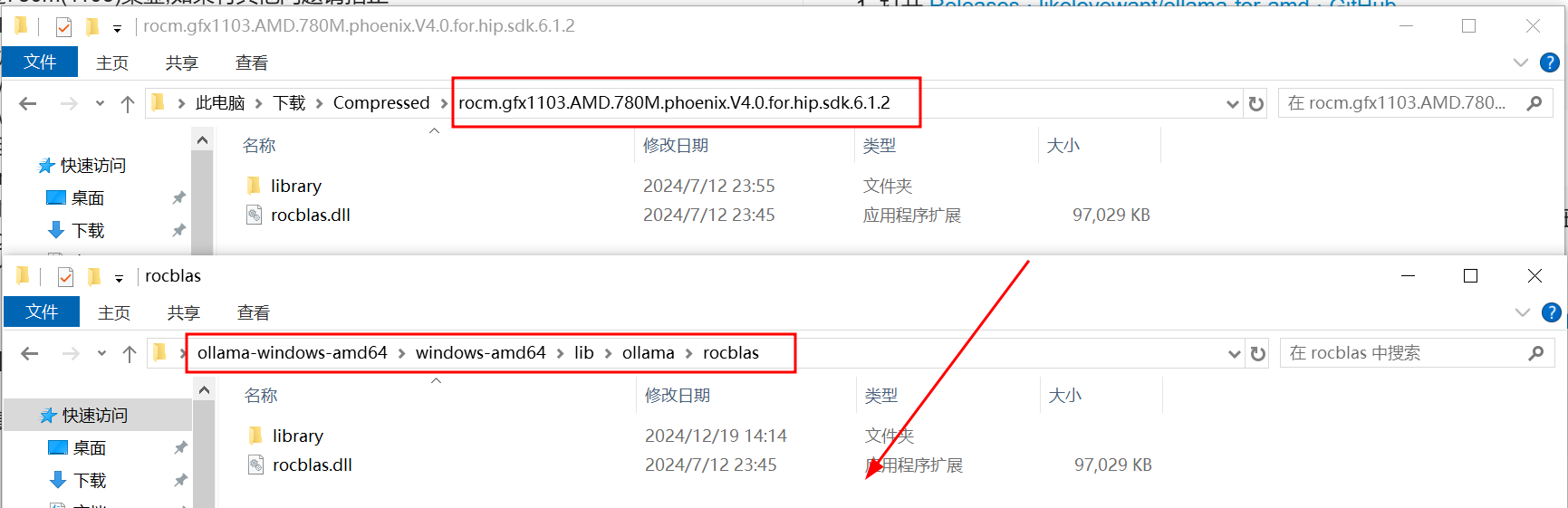
- 解压第2步

- 解压第3步并复制到这里
rocm.gfx1103.AMD.780M.phoenix.V5.0.for.hip.sdk.6.2.4 => ollama-windows-amd64\windows-amd64\lib\ollama\rocm\rocblas
覆盖
- 启动
- ./ollama.exe serve
- 测试日志
- 供大家参考
➜ windows-amd64 OLLAMA_DEBUG=1 ./ollama.exe serve
2025/02/01 21:03:31 routes.go:1259: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:true OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\chen\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES:]"
time=2025-02-01T21:03:31.971+08:00 level=INFO source=images.go:757 msg="total blobs: 10"
time=2025-02-01T21:03:31.971+08:00 level=INFO source=images.go:764 msg="total unused blobs removed: 0"
time=2025-02-01T21:03:31.972+08:00 level=INFO source=routes.go:1310 msg="Listening on 127.0.0.1:11434 (version 0.5.4-0-g08b8916)"
time=2025-02-01T21:03:31.972+08:00 level=DEBUG source=common.go:80 msg="runners located" dir=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners
time=2025-02-01T21:03:31.973+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\cpu_avx\ollama_llama_server.exe
time=2025-02-01T21:03:31.974+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\cpu_avx2\ollama_llama_server.exe
time=2025-02-01T21:03:31.974+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\rocm_avx\ollama_llama_server.exe
time=2025-02-01T21:03:31.974+08:00 level=INFO source=routes.go:1339 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 rocm_avx]"
time=2025-02-01T21:03:31.974+08:00 level=DEBUG source=routes.go:1340 msg="Override detection logic by setting OLLAMA_LLM_LIBRARY"
time=2025-02-01T21:03:31.974+08:00 level=DEBUG source=sched.go:105 msg="starting llm scheduler"
time=2025-02-01T21:03:31.974+08:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2025-02-01T21:03:31.974+08:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2025-02-01T21:03:31.974+08:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=8 efficiency=0 threads=16
time=2025-02-01T21:03:31.974+08:00 level=DEBUG source=gpu.go:99 msg="searching for GPU discovery libraries for NVIDIA"
time=2025-02-01T21:03:31.974+08:00 level=DEBUG source=gpu.go:517 msg="Searching for GPU library" name=nvml.dll
time=2025-02-01T21:03:31.974+08:00 level=DEBUG source=gpu.go:543 msg="gpu library search" globs="[C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\nvml.dll C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\nvml.dll C:\\extension\\ffmpeg\\bin\\nvml.dll C:\\extension\\nvml.dll C:\\msys64\\usr\\local\\bin\\nvml.dll C:\\Users\\chen\\AppData\\Local\\fnm_multishells\\32_1738407323091\\nvml.dll C:\\msys64\\ucrt64\\bin\\nvml.dll C:\\msys64\\usr\\local\\bin\\nvml.dll C:\\msys64\\usr\\bin\\nvml.dll C:\\msys64\\usr\\bin\\nvml.dll C:\\Windows\\system32\\nvml.dll C:\\Windows\\nvml.dll C:\\Windows\\System32\\Wbem\\nvml.dll C:\\Windows\\System32\\WindowsPowerShell\\v1.0\\nvml.dll C:\\Windows\\System32\\OpenSSH\\nvml.dll C:\\Program Files\\Tailscale\\nvml.dll C:\\Program Files\\Calibre2\\nvml.dll C:\\Program Files\\dotnet\\nvml.dll C:\\Program Files\\Docker\\Docker\\resources\\bin\\nvml.dll C:\\Program Files\\Go\\bin\\nvml.dll C:\\extension\\ffmpeg\\bin\\nvml.dll C:\\Users\\chen\\.cargo\\bin\\nvml.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312\\Scripts\\nvml.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312\\nvml.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Launcher\\nvml.dll C:\\Users\\chen\\AppData\\Local\\Microsoft\\WindowsApps\\nvml.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Microsoft VS Code\\bin\\nvml.dll C:\\msys64\\extension\\git\\bin\\nvml.dll C:\\msys64\\usr\\bin\\nvml.dll C:\\extension\\fnm-windows\\nvml.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Ollama\\nvml.dll C:\\Users\\chen\\go\\bin\\nvml.dll C:\\Users\\chen\\AppData\\Local\\Programs\\ShengHuaBi\\bin\\nvml.dll C:\\msys64\\usr\\bin\\site_perl\\nvml.dll C:\\msys64\\usr\\bin\\vendor_perl\\nvml.dll C:\\msys64\\usr\\bin\\core_perl\\nvml.dll c:\\Windows\\System32\\nvml.dll]"
time=2025-02-01T21:03:31.977+08:00 level=DEBUG source=gpu.go:577 msg="discovered GPU libraries" paths=[]
time=2025-02-01T21:03:31.977+08:00 level=DEBUG source=gpu.go:517 msg="Searching for GPU library" name=nvcuda.dll
time=2025-02-01T21:03:31.977+08:00 level=DEBUG source=gpu.go:543 msg="gpu library search" globs="[C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\nvcuda.dll C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\nvcuda.dll C:\\extension\\ffmpeg\\bin\\nvcuda.dll C:\\extension\\nvcuda.dll C:\\msys64\\usr\\local\\bin\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\fnm_multishells\\32_1738407323091\\nvcuda.dll C:\\msys64\\ucrt64\\bin\\nvcuda.dll C:\\msys64\\usr\\local\\bin\\nvcuda.dll C:\\msys64\\usr\\bin\\nvcuda.dll C:\\msys64\\usr\\bin\\nvcuda.dll C:\\Windows\\system32\\nvcuda.dll C:\\Windows\\nvcuda.dll C:\\Windows\\System32\\Wbem\\nvcuda.dll C:\\Windows\\System32\\WindowsPowerShell\\v1.0\\nvcuda.dll C:\\Windows\\System32\\OpenSSH\\nvcuda.dll C:\\Program Files\\Tailscale\\nvcuda.dll C:\\Program Files\\Calibre2\\nvcuda.dll C:\\Program Files\\dotnet\\nvcuda.dll C:\\Program Files\\Docker\\Docker\\resources\\bin\\nvcuda.dll C:\\Program Files\\Go\\bin\\nvcuda.dll C:\\extension\\ffmpeg\\bin\\nvcuda.dll C:\\Users\\chen\\.cargo\\bin\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312\\Scripts\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Launcher\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\Microsoft\\WindowsApps\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Microsoft VS Code\\bin\\nvcuda.dll C:\\msys64\\extension\\git\\bin\\nvcuda.dll C:\\msys64\\usr\\bin\\nvcuda.dll C:\\extension\\fnm-windows\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Ollama\\nvcuda.dll C:\\Users\\chen\\go\\bin\\nvcuda.dll C:\\Users\\chen\\AppData\\Local\\Programs\\ShengHuaBi\\bin\\nvcuda.dll C:\\msys64\\usr\\bin\\site_perl\\nvcuda.dll C:\\msys64\\usr\\bin\\vendor_perl\\nvcuda.dll C:\\msys64\\usr\\bin\\core_perl\\nvcuda.dll c:\\windows\\system*\\nvcuda.dll]"
time=2025-02-01T21:03:31.980+08:00 level=DEBUG source=gpu.go:577 msg="discovered GPU libraries" paths=[]
time=2025-02-01T21:03:31.980+08:00 level=DEBUG source=gpu.go:517 msg="Searching for GPU library" name=cudart64_*.dll
time=2025-02-01T21:03:31.980+08:00 level=DEBUG source=gpu.go:543 msg="gpu library search" globs="[C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\cudart64_*.dll C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\cudart64_*.dll C:\\extension\\ffmpeg\\bin\\cudart64_*.dll C:\\extension\\cudart64_*.dll C:\\msys64\\usr\\local\\bin\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\fnm_multishells\\32_1738407323091\\cudart64_*.dll C:\\msys64\\ucrt64\\bin\\cudart64_*.dll C:\\msys64\\usr\\local\\bin\\cudart64_*.dll C:\\msys64\\usr\\bin\\cudart64_*.dll C:\\msys64\\usr\\bin\\cudart64_*.dll C:\\Windows\\system32\\cudart64_*.dll C:\\Windows\\cudart64_*.dll C:\\Windows\\System32\\Wbem\\cudart64_*.dll C:\\Windows\\System32\\WindowsPowerShell\\v1.0\\cudart64_*.dll C:\\Windows\\System32\\OpenSSH\\cudart64_*.dll C:\\Program Files\\Tailscale\\cudart64_*.dll C:\\Program Files\\Calibre2\\cudart64_*.dll C:\\Program Files\\dotnet\\cudart64_*.dll C:\\Program Files\\Docker\\Docker\\resources\\bin\\cudart64_*.dll C:\\Program Files\\Go\\bin\\cudart64_*.dll C:\\extension\\ffmpeg\\bin\\cudart64_*.dll C:\\Users\\chen\\.cargo\\bin\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312\\Scripts\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Launcher\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Microsoft\\WindowsApps\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Microsoft VS Code\\bin\\cudart64_*.dll C:\\msys64\\extension\\git\\bin\\cudart64_*.dll C:\\msys64\\usr\\bin\\cudart64_*.dll C:\\extension\\fnm-windows\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Ollama\\cudart64_*.dll C:\\Users\\chen\\go\\bin\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Programs\\ShengHuaBi\\bin\\cudart64_*.dll C:\\msys64\\usr\\bin\\site_perl\\cudart64_*.dll C:\\msys64\\usr\\bin\\vendor_perl\\cudart64_*.dll C:\\msys64\\usr\\bin\\core_perl\\cudart64_*.dll C:\\Users\\chen\\AppData\\Local\\Programs\\Ollama\\cudart64_*.dll C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\cudart64_*.dll C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\cudart64_*.dll c:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v*\\bin\\cudart64_*.dll]"
time=2025-02-01T21:03:31.991+08:00 level=DEBUG source=gpu.go:577 msg="discovered GPU libraries" paths=[]
time=2025-02-01T21:03:32.014+08:00 level=DEBUG source=amd_hip_windows.go:88 msg=hipDriverGetVersion version=60241512
time=2025-02-01T21:03:32.014+08:00 level=DEBUG source=amd_common.go:18 msg="evaluating potential rocm lib dir C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama"
time=2025-02-01T21:03:32.015+08:00 level=DEBUG source=amd_common.go:48 msg="detected ROCM next to ollama executable C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama"
time=2025-02-01T21:03:32.016+08:00 level=DEBUG source=amd_windows.go:75 msg="detected hip devices" count=1
time=2025-02-01T21:03:32.016+08:00 level=DEBUG source=amd_windows.go:95 msg="hip device" id=0 name="AMD Radeon 780M Graphics" gfx=gfx1103
time=2025-02-01T21:03:32.365+08:00 level=DEBUG source=amd_windows.go:148 msg="amdgpu is supported" gpu=0 gpu_type=gfx1103
time=2025-02-01T21:03:32.365+08:00 level=DEBUG source=amd_windows.go:151 msg="amdgpu memory" gpu=0 total="12.2 GiB"
time=2025-02-01T21:03:32.365+08:00 level=DEBUG source=amd_windows.go:152 msg="amdgpu memory" gpu=0 available="12.0 GiB"
time=2025-02-01T21:03:32.367+08:00 level=INFO source=types.go:131 msg="inference compute" id=0 library=rocm variant="" compute=gfx1103 driver=6.2 name="AMD Radeon 780M Graphics" total="12.2 GiB" available="12.0 GiB"
[GIN] 2025/02/01 - 21:03:41 | 200 | 0s | 127.0.0.1 | HEAD "/"
[GIN] 2025/02/01 - 21:03:41 | 200 | 1.6236ms | 127.0.0.1 | GET "/api/tags"
time=2025-02-01T21:03:41.593+08:00 level=DEBUG source=gpu.go:406 msg="updating system memory data" before.total="31.2 GiB" before.free="18.5 GiB" before.free_swap="18.4 GiB" now.total="31.2 GiB" now.free="18.4 GiB" now.free_swap="18.1 GiB"
time=2025-02-01T21:03:41.944+08:00 level=DEBUG source=amd_windows.go:201 msg="updating rocm free memory" gpu=0 name="AMD Radeon 780M Graphics" before="12.0 GiB" now="11.9 GiB"
time=2025-02-01T21:03:41.947+08:00 level=INFO source=sched.go:185 msg="one or more GPUs detected that are unable to accurately report free memory - disabling default concurrency"
time=2025-02-01T21:03:41.971+08:00 level=DEBUG source=sched.go:224 msg="loading first model" model=C:\Users\chen\.ollama\models\blobs\sha256-2bada8a7450677000f678be90653b85d364de7db25eb5ea54136ada5f3933730
time=2025-02-01T21:03:41.971+08:00 level=DEBUG source=memory.go:107 msg=evaluating library=rocm gpu_count=1 available="[11.9 GiB]"
time=2025-02-01T21:03:41.971+08:00 level=DEBUG source=memory.go:107 msg=evaluating library=rocm gpu_count=1 available="[11.9 GiB]"
time=2025-02-01T21:03:41.972+08:00 level=INFO source=sched.go:714 msg="new model will fit in available VRAM in single GPU, loading" model=C:\Users\chen\.ollama\models\blobs\sha256-2bada8a7450677000f678be90653b85d364de7db25eb5ea54136ada5f3933730 gpu=0 parallel=1 available=12781334528 required="8.3 GiB"
time=2025-02-01T21:03:41.972+08:00 level=DEBUG source=gpu.go:406 msg="updating system memory data" before.total="31.2 GiB" before.free="18.4 GiB" before.free_swap="18.1 GiB" now.total="31.2 GiB" now.free="18.2 GiB" now.free_swap="18.0 GiB"
time=2025-02-01T21:03:43.014+08:00 level=DEBUG source=amd_windows.go:201 msg="updating rocm free memory" gpu=0 name="AMD Radeon 780M Graphics" before="11.9 GiB" now="11.8 GiB"
time=2025-02-01T21:03:43.017+08:00 level=INFO source=server.go:104 msg="system memory" total="31.2 GiB" free="18.2 GiB" free_swap="18.0 GiB"
time=2025-02-01T21:03:43.017+08:00 level=DEBUG source=memory.go:107 msg=evaluating library=rocm gpu_count=1 available="[11.9 GiB]"
time=2025-02-01T21:03:43.017+08:00 level=INFO source=memory.go:356 msg="offload to rocm" layers.requested=-1 layers.model=29 layers.offload=29 layers.split="" memory.available="[11.9 GiB]" memory.gpu_overhead="0 B" memory.required.full="8.3 GiB" memory.required.partial="8.3 GiB" memory.required.kv="1.8 GiB" memory.required.allocations="[8.3 GiB]" memory.weights.total="5.4 GiB" memory.weights.repeating="5.0 GiB" memory.weights.nonrepeating="426.4 MiB" memory.graph.full="1.8 GiB" memory.graph.partial="2.3 GiB"
time=2025-02-01T21:03:43.018+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\cpu_avx\ollama_llama_server.exe
time=2025-02-01T21:03:43.018+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\cpu_avx2\ollama_llama_server.exe
time=2025-02-01T21:03:43.018+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\rocm_avx\ollama_llama_server.exe
time=2025-02-01T21:03:43.019+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\cpu_avx\ollama_llama_server.exe
time=2025-02-01T21:03:43.019+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\cpu_avx2\ollama_llama_server.exe
time=2025-02-01T21:03:43.019+08:00 level=DEBUG source=common.go:124 msg="availableServers : found" file=C:\Users\chen\Desktop\ollama-windows-amd64\windows-amd64\lib\ollama\runners\rocm_avx\ollama_llama_server.exe
time=2025-02-01T21:03:43.030+08:00 level=INFO source=server.go:376 msg="starting llama server" cmd="C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\runners\\rocm_avx\\ollama_llama_server.exe runner --model C:\\Users\\chen\\.ollama\\models\\blobs\\sha256-2bada8a7450677000f678be90653b85d364de7db25eb5ea54136ada5f3933730 --ctx-size 32768 --batch-size 512 --n-gpu-layers 29 --verbose --threads 8 --parallel 1 --port 52679"
time=2025-02-01T21:03:43.030+08:00 level=DEBUG source=server.go:393 msg=subprocess environment="[PATH=C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama;C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama;C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama;C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64\\lib\\ollama\\runners\\rocm_avx;C:\\extension\\ffmpeg\\bin;C:\\extension;C:\\msys64\\usr\\local\\bin;C:\\Users\\chen\\AppData\\Local\\fnm_multishells\\32_1738407323091;C:\\msys64\\ucrt64\\bin;C:\\msys64\\usr\\local\\bin;C:\\msys64\\usr\\bin;C:\\msys64\\usr\\bin;C:\\Windows\\system32;C:\\Windows;C:\\Windows\\System32\\Wbem;C:\\Windows\\System32\\WindowsPowerShell\\v1.0;C:\\Windows\\System32\\OpenSSH;C:\\Program Files\\Tailscale;C:\\Program Files\\Calibre2;C:\\Program Files\\dotnet;C:\\Program Files\\Docker\\Docker\\resources\\bin;C:\\Program Files\\Go\\bin;C:\\extension\\ffmpeg\\bin;C:\\Users\\chen\\.cargo\\bin;C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312\\Scripts;C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Python312;C:\\Users\\chen\\AppData\\Local\\Programs\\Python\\Launcher;C:\\Users\\chen\\AppData\\Local\\Microsoft\\WindowsApps;C:\\Users\\chen\\AppData\\Local\\Programs\\Microsoft VS Code\\bin;C:\\msys64\\extension\\git\\bin;C:\\msys64\\usr\\bin;C:\\extension\\fnm-windows;C:\\Users\\chen\\AppData\\Local\\Programs\\Ollama;C:\\Users\\chen\\go\\bin;C:\\Users\\chen\\AppData\\Local\\Programs\\ShengHuaBi\\bin;C:\\msys64\\usr\\bin\\site_perl;C:\\msys64\\usr\\bin\\vendor_perl;C:\\msys64\\usr\\bin\\core_perl HIP_VISIBLE_DEVICES=0]"
time=2025-02-01T21:03:43.061+08:00 level=INFO source=sched.go:449 msg="loaded runners" count=1
time=2025-02-01T21:03:43.061+08:00 level=INFO source=server.go:555 msg="waiting for llama runner to start responding"
time=2025-02-01T21:03:43.062+08:00 level=INFO source=server.go:589 msg="waiting for server to become available" status="llm server error"
time=2025-02-01T21:03:43.101+08:00 level=INFO source=runner.go:938 msg="starting go runner"
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 ROCm devices:
Device 0: AMD Radeon 780M Graphics, compute capability 11.0, VMM: no
time=2025-02-01T21:03:47.311+08:00 level=INFO source=runner.go:939 msg=system info="ROCm : NO_PEER_COPY = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | LLAMAFILE = 1 | AARCH64_REPACK = 1 | cgo(clang)" threads=8
llama_load_model_from_file: using device ROCm0 (AMD Radeon 780M Graphics) - 12075 MiB free
time=2025-02-01T21:03:47.312+08:00 level=INFO source=.:0 msg="Server listening on 127.0.0.1:52679"
time=2025-02-01T21:03:47.336+08:00 level=INFO source=server.go:589 msg="waiting for server to become available" status="llm server loading model"
llama_model_loader: loaded meta data with 34 key-value pairs and 339 tensors from C:\Users\chen\.ollama\models\blobs\sha256-2bada8a7450677000f678be90653b85d364de7db25eb5ea54136ada5f3933730 (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Qwen2.5 7B Instruct
llama_model_loader: - kv 3: general.finetune str = Instruct
llama_model_loader: - kv 4: general.basename str = Qwen2.5
llama_model_loader: - kv 5: general.size_label str = 7B
llama_model_loader: - kv 6: general.license str = apache-2.0
llama_model_loader: - kv 7: general.license.link str = https://huggingface.co/Qwen/Qwen2.5-7...
llama_model_loader: - kv 8: general.base_model.count u32 = 1
llama_model_loader: - kv 9: general.base_model.0.name str = Qwen2.5 7B
llama_model_loader: - kv 10: general.base_model.0.organization str = Qwen
llama_model_loader: - kv 11: general.base_model.0.repo_url str = https://huggingface.co/Qwen/Qwen2.5-7B
llama_model_loader: - kv 12: general.tags arr[str,2] = ["chat", "text-generation"]
llama_model_loader: - kv 13: general.languages arr[str,1] = ["en"]
llama_model_loader: - kv 14: qwen2.block_count u32 = 28
llama_model_loader: - kv 15: qwen2.context_length u32 = 32768
llama_model_loader: - kv 16: qwen2.embedding_length u32 = 3584
llama_model_loader: - kv 17: qwen2.feed_forward_length u32 = 18944
llama_model_loader: - kv 18: qwen2.attention.head_count u32 = 28
llama_model_loader: - kv 19: qwen2.attention.head_count_kv u32 = 4
llama_model_loader: - kv 20: qwen2.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 21: qwen2.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 22: general.file_type u32 = 15
llama_model_loader: - kv 23: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 24: tokenizer.ggml.pre str = qwen2
llama_model_loader: - kv 25: tokenizer.ggml.tokens arr[str,152064] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 26: tokenizer.ggml.token_type arr[i32,152064] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 27: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 28: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 29: tokenizer.ggml.padding_token_id u32 = 151643
llama_model_loader: - kv 30: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 31: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 32: tokenizer.chat_template str = {%- if tools %}\n {{- '<|im_start|>...
llama_model_loader: - kv 33: general.quantization_version u32 = 2
llama_model_loader: - type f32: 141 tensors
llama_model_loader: - type q4_K: 169 tensors
llama_model_loader: - type q6_K: 29 tensors
llm_load_vocab: control token: 151659 '<|fim_prefix|>' is not marked as EOG
llm_load_vocab: control token: 151656 '<|video_pad|>' is not marked as EOG
llm_load_vocab: control token: 151655 '<|image_pad|>' is not marked as EOG
llm_load_vocab: control token: 151653 '<|vision_end|>' is not marked as EOG
llm_load_vocab: control token: 151652 '<|vision_start|>' is not marked as EOG
llm_load_vocab: control token: 151651 '<|quad_end|>' is not marked as EOG
llm_load_vocab: control token: 151649 '<|box_end|>' is not marked as EOG
llm_load_vocab: control token: 151648 '<|box_start|>' is not marked as EOG
llm_load_vocab: control token: 151646 '<|object_ref_start|>' is not marked as EOG
llm_load_vocab: control token: 151644 '<|im_start|>' is not marked as EOG
llm_load_vocab: control token: 151661 '<|fim_suffix|>' is not marked as EOG
llm_load_vocab: control token: 151647 '<|object_ref_end|>' is not marked as EOG
llm_load_vocab: control token: 151660 '<|fim_middle|>' is not marked as EOG
llm_load_vocab: control token: 151654 '<|vision_pad|>' is not marked as EOG
llm_load_vocab: control token: 151650 '<|quad_start|>' is not marked as EOG
llm_load_vocab: special tokens cache size = 22
llm_load_vocab: token to piece cache size = 0.9310 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = qwen2
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 152064
llm_load_print_meta: n_merges = 151387
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 32768
llm_load_print_meta: n_embd = 3584
llm_load_print_meta: n_layer = 28
llm_load_print_meta: n_head = 28
llm_load_print_meta: n_head_kv = 4
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 7
llm_load_print_meta: n_embd_k_gqa = 512
llm_load_print_meta: n_embd_v_gqa = 512
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 18944
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 2
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 1000000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 32768
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: ssm_dt_b_c_rms = 0
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q4_K - Medium
llm_load_print_meta: model params = 7.62 B
llm_load_print_meta: model size = 4.36 GiB (4.91 BPW)
llm_load_print_meta: general.name = Qwen2.5 7B Instruct
llm_load_print_meta: BOS token = 151643 '<|endoftext|>'
llm_load_print_meta: EOS token = 151645 '<|im_end|>'
llm_load_print_meta: EOT token = 151645 '<|im_end|>'
llm_load_print_meta: PAD token = 151643 '<|endoftext|>'
llm_load_print_meta: LF token = 148848 'ÄĬ'
llm_load_print_meta: FIM PRE token = 151659 '<|fim_prefix|>'
llm_load_print_meta: FIM SUF token = 151661 '<|fim_suffix|>'
llm_load_print_meta: FIM MID token = 151660 '<|fim_middle|>'
llm_load_print_meta: FIM PAD token = 151662 '<|fim_pad|>'
llm_load_print_meta: FIM REP token = 151663 '<|repo_name|>'
llm_load_print_meta: FIM SEP token = 151664 '<|file_sep|>'
llm_load_print_meta: EOG token = 151643 '<|endoftext|>'
llm_load_print_meta: EOG token = 151645 '<|im_end|>'
llm_load_print_meta: EOG token = 151662 '<|fim_pad|>'
llm_load_print_meta: EOG token = 151663 '<|repo_name|>'
llm_load_print_meta: EOG token = 151664 '<|file_sep|>'
llm_load_print_meta: max token length = 256
llm_load_tensors: tensor 'token_embd.weight' (q4_K) (and 0 others) cannot be used with preferred buffer type CPU_AARCH64, using CPU instead
llm_load_tensors: offloading 28 repeating layers to GPU
llm_load_tensors: offloading output layer to GPU
llm_load_tensors: offloaded 29/29 layers to GPU
llm_load_tensors: CPU_Mapped model buffer size = 292.36 MiB
llm_load_tensors: ROCm0 model buffer size = 4168.09 MiB
time=2025-02-01T21:03:51.096+08:00 level=DEBUG source=server.go:600 msg="model load progress 0.18"
time=2025-02-01T21:03:51.347+08:00 level=DEBUG source=server.go:600 msg="model load progress 0.36"
time=2025-02-01T21:03:51.597+08:00 level=DEBUG source=server.go:600 msg="model load progress 0.52"
time=2025-02-01T21:03:51.848+08:00 level=DEBUG source=server.go:600 msg="model load progress 0.68"
time=2025-02-01T21:03:52.098+08:00 level=DEBUG source=server.go:600 msg="model load progress 0.86"
其他问题
是否需要安装官方的hips sdk
- 应该不需要,因为我目前没有安装并且正常运行了,并且官方也没有为不支持的设备进行编译,ollama目前是自带hips sdk,所以直接像第五步把文件覆盖过去就可以了
编辑器上如何使用第三方ollama
- 设置配置
"shenghuabi.ollama.dir": "C:\\Users\\chen\\Desktop\\ollama-windows-amd64\\windows-amd64",
- 参考第四步截图的位置