启动时弹出帮助页面
- 如果在非首次配置的情况下弹出帮助页面,那么说明
工作区和环境配置文件夹至少有一个没有配置 - 比如您使用右键打开某个文件
- 这时找到之前的工作区重新打开,或者关闭后找到之前的工作区右键打开
配置丢失?
- 右键打开某个文件夹,那么当前文件夹就是一个新的工作区,而相关可能配置在之前的工作区上
- 找到之前的工作区,然后右键打开即可
安装是否需要python环境
- 不需要软件帮你了
安装是否需要特殊的网络环境
- 不需要软件帮你了
下载失败怎么办?
-
所有下载地址都做了镜像源下载,包括软件,也就是只要软件能下载,那么基本上都能下载
-
如果遇到下载慢或者无法下载的情况下,建议不同时间段进行下载测试,因为cf加速有些时候访问确实不好
-
软件部分下载(不是模型)失败可以尝试使用下面配置,修改后重启生效
"shenghuabi.download": {
"softwareMirror": "github-release2.tbontop.top"
}
gb2312编码乱码?
- 右下角会有一个选择编码的按钮(上面的字可能是UT8或者其他的),点击后出现弹窗,通过编码重新打开,文本正常后。改成utf8在重新保存
- 导入知识库中的文本会自动猜测编码
括号颜色
- 可以左下角设置中修改
"workbench.colorCustomizations": {
"editorBracketHighlight.foreground1": "#45aa79",
}
- 另外我看了后才发现没区分各种括号类型。所以这个样式的修改是所有括号颜色统一改的。未来会改成那种允许不同类型的括号不同颜色的设置
直接下载优先
- 这个的真实意思就是,直接连接 github. huggingface等网站进行下载,不用镜像源。所以默认是不开启的。如果你非要用,请保证你能访问这些网站
为什么嵌入模型下载到100%后会卡住/ocr识别失败/知识库创建卡住
- windows下transformers默认使用dml进行文本嵌入和ocr,其对设备要求如下
* AMD GCN 1st Gen (Radeon HD 7000 series) and above
* Intel Haswell (4th-gen core) HD Integrated Graphics and above
* NVIDIA Kepler (GTX 600 series) and above
* Qualcomm Adreno 600 and above
- 理论上不是太老的设备都支持
解决方案
- 尝试安装最新驱动
- 将配置中的dml改为cpu
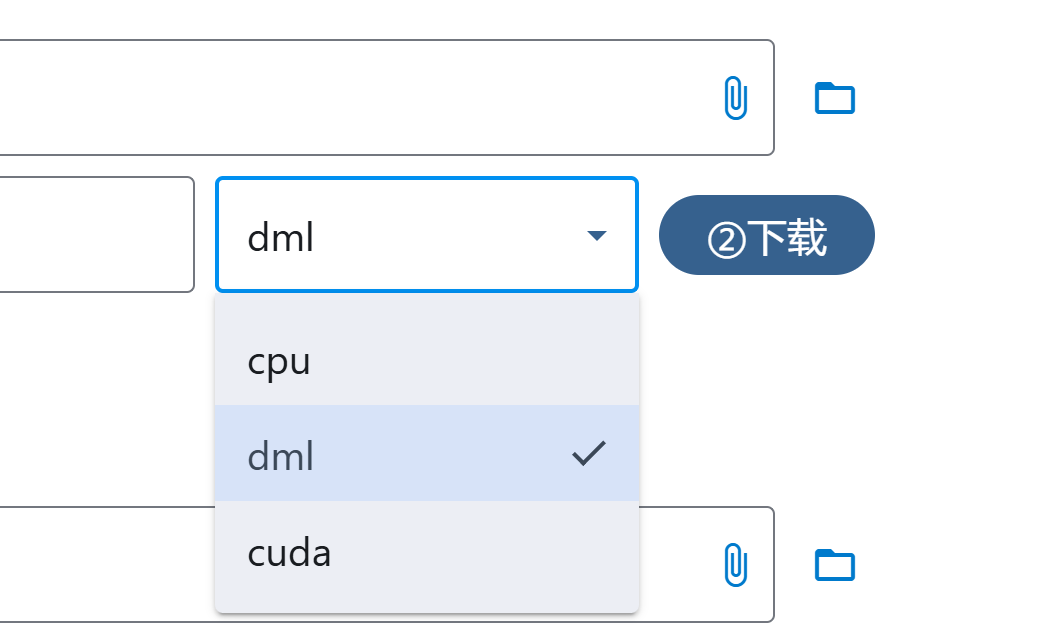
- 如果设备实在过老可以使用Ollama的词嵌入模型
bge-m3,只不过会慢很多(不知道为什么似乎不支持批量处理,传递的是一个数组,但是实际上会一个一个执行…) - 直接调用openai兼容的api
使用ollama对话时为什么比较慢
- ollama不支持当前gpu设备加速推理
- 爆显存
排查方案
- 保证显卡最新驱动已经安装
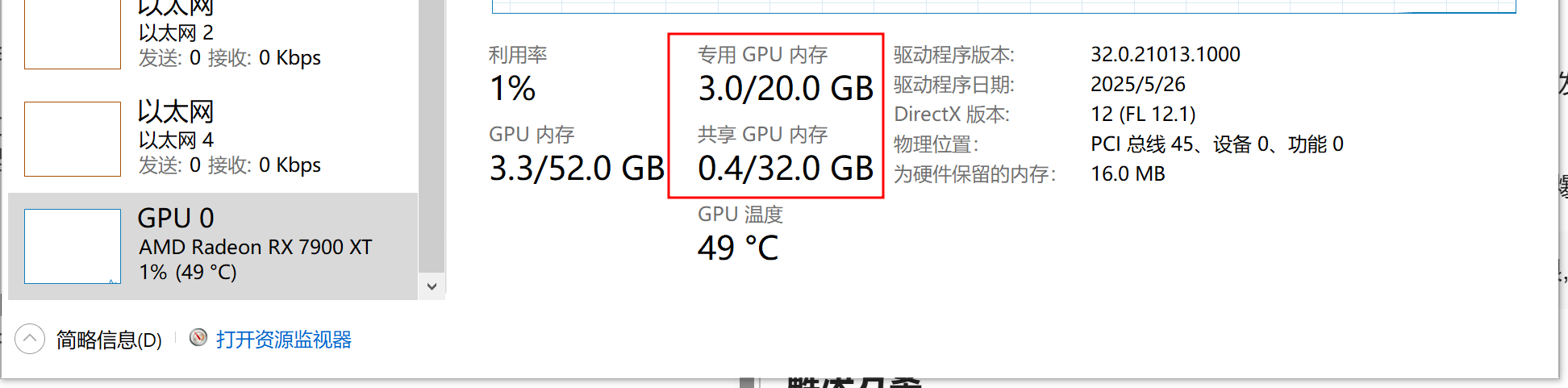
- 当模型被加载并且进行输出时,查看
任务管理器中GPU内存是否有高占用
8 B q4 大概4G以上, q8 8G以上,基本上就是按照这个模数估算
-
推理速度可以简单用带宽除以模型大小(moe为每个激活的大小),一般达到这个计算结果的80%左右就可以认为正常,如果低于这个,不是爆显存,就是没有用gpu推理
-
如果说gpu部分看到显存占用上去了,那么就是支持推理,如果说发现推理时只有cpu部分变高,那么就是不支持gpu加速推理
-
如果说gpu显存占用升高,并且接近显存上限,那么基本上就说明爆显存了
因为没爆显存和爆显存速度差距是比较明显的再加上到了显存上限,很容易推断
解决方案
爆显存
- 请先停止ollama,然后调低如下参数,然后再启动
"shenghuabi.ollama.env": {
"OLLAMA_CONTEXT_LENGTH": 200
},
- 如果这时速度恢复正常,那么可以适当调高上下文长度重复操作,直到接近极限
- 如果任务管理器部分仍然出现内存,显存同步升高的情况,那么就说明当前模型过大,强制使用速度就会变慢
非ollama官方支持的显卡
- 由于目前ollama只支持cuda,rocm的部分显卡加速,所有有很多显卡并不在支持范围内
- amd的集显和老显卡的定制版ollama
- intel定制ollama
- 使用llama.cpp 的vulkan加速