版本要求 1.103.25以上
目前支持IndexTTS的文本转音频
目前支持Windows(cpu,cuda,zluda),Linux(cpu,cuda,rocm)设备
设备
- zluda windows上a卡使用cuda的一个兼容
hip官方支持的不需要改,不支持的还需要单独修改驱动
- directml测试无法运行tts,可能是微软的问题…
最新支持torch 2.4.1…比amd都懒,感觉是不更新了?
安装
-
理论上使用时会自动安装(如果不存在),但是为了防止下载时卡住,所以建议还是先下载
-
下载安装包与模型
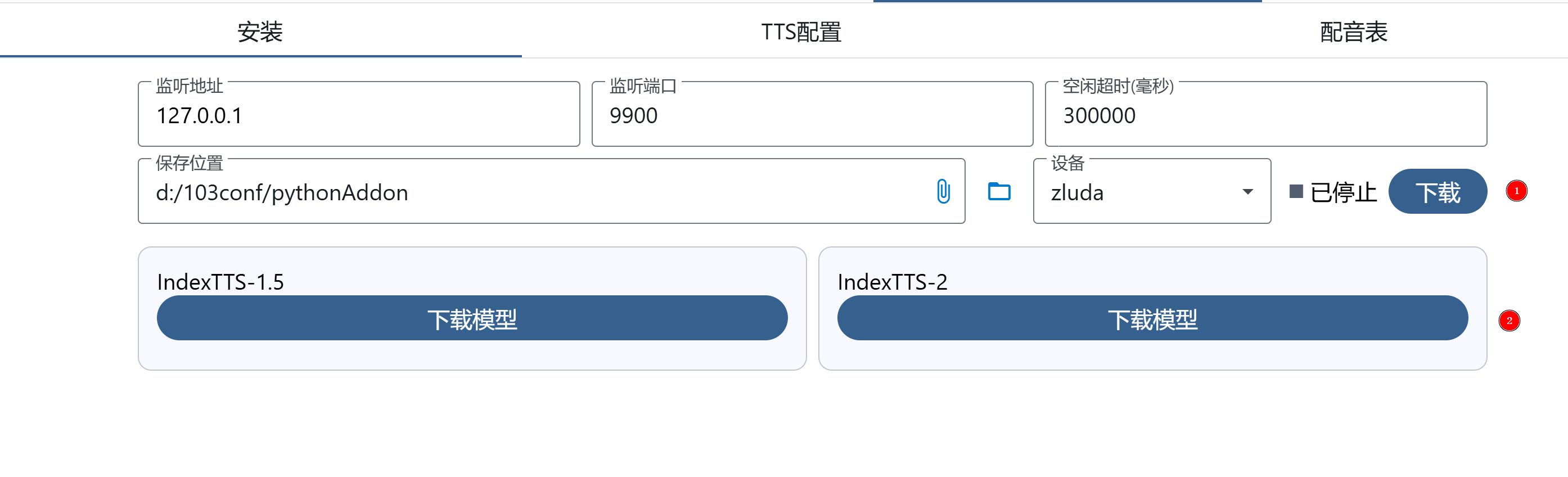
- 下载tts一键包
- 下载模型,可以根据机器性能选择1.5/2
2占用内存较大N卡8G左右,A卡会更大
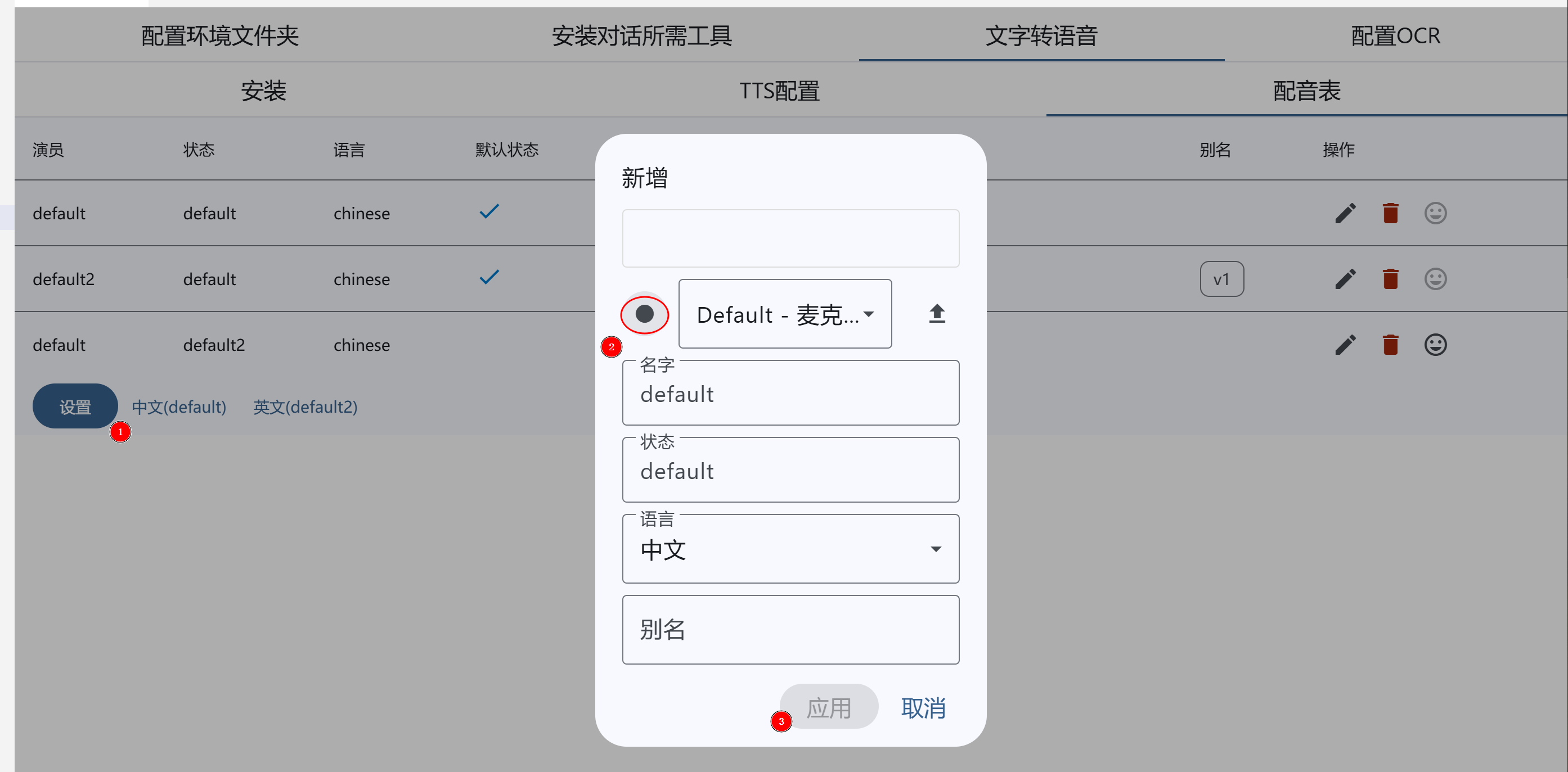
设置配音
- 文本生成语音之前需要先设置配音,然后生成的语音就会以提供的配音样本为准进行生成
右下角可能会弹出调用麦克风请求(如果有杀毒软件)
文本生成语音
- 选择
工作区中的文件 - 点击右上角
文本到语音处理
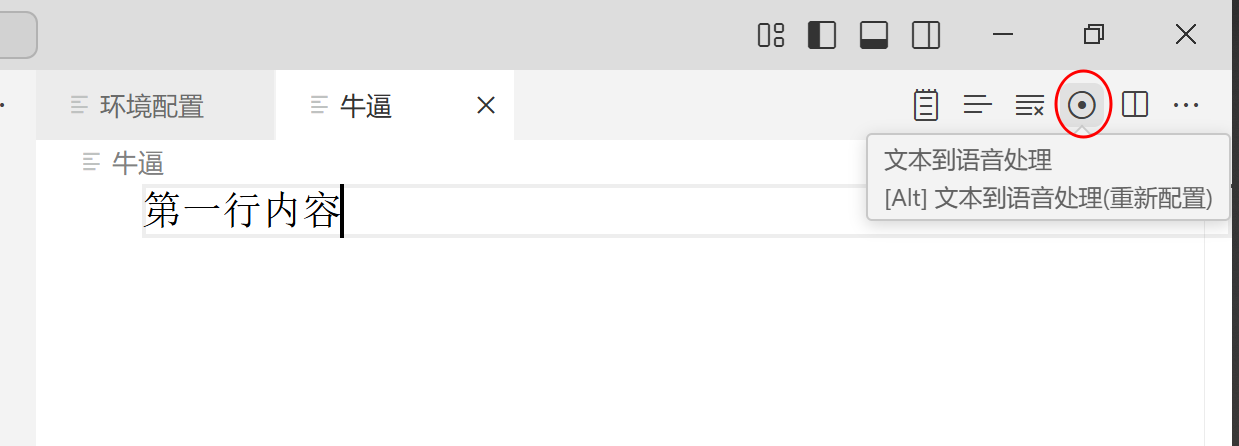
- 弹出页面后点击生成即可
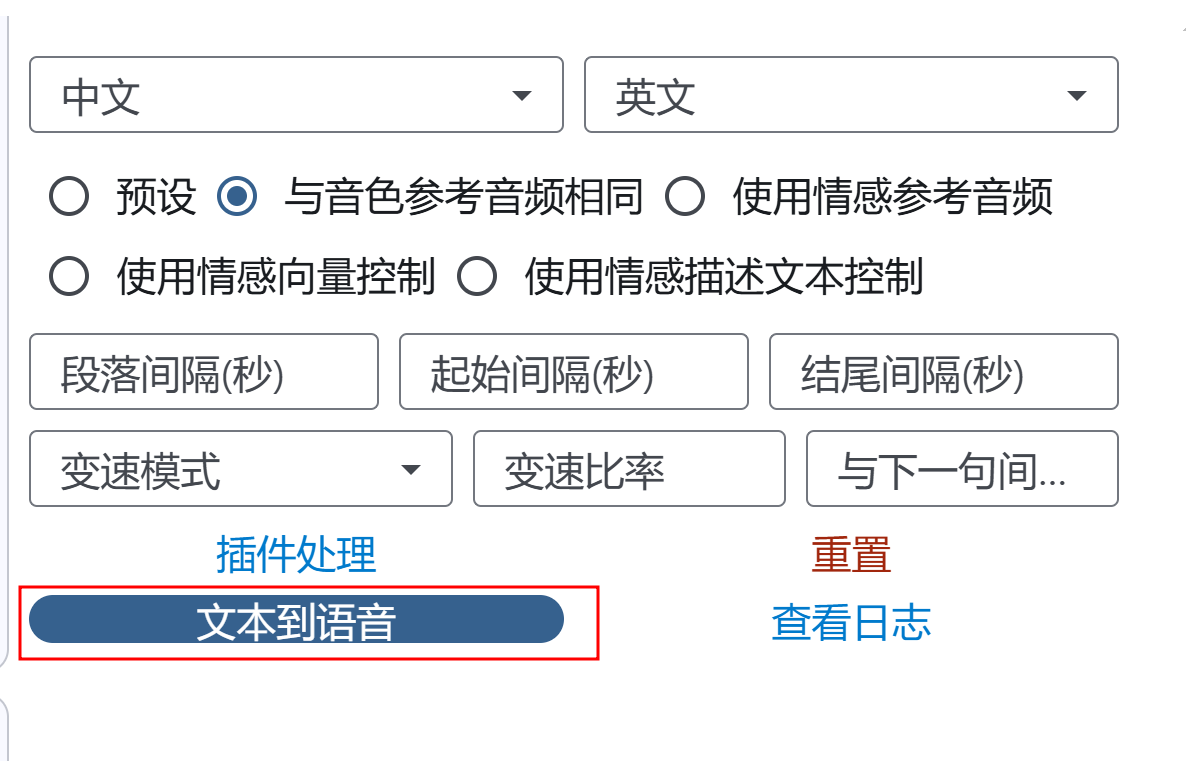
新配置部分
- 生成部分被重构,其他基本一样
[新]TTS-文本生成语音
缓存
- 默认情况下,每段生成的音频都会进行缓存,在每分句配置不变的情况下,会采用之前生成的音频,方便进行修改
自动分句
- 默认情况下会尝试将文本中的对话部分单独提取出来,并尝试在配音表中找到对应的配置
如xxx说:“yyyy”,会尝试在配音表中找到xxx,并以相关引用音频应用到
yyyy文本中
选择工作流处理
- 默认情况下,使用
default/[TTS]基础文本解析工作流,可以自动处理文本和字幕.
常规处理,解析后需要自己根据上下文编辑
- 如果需要自定义解析,可以使用插件,安装后创建工作流
- 按住
Alt键再点击文本到语音处理会出现选择工作流,选择创建好的工作流
按住Alt选择表示重新选择工作流处理,也就是下次不按的话,会按照上一次选择的值