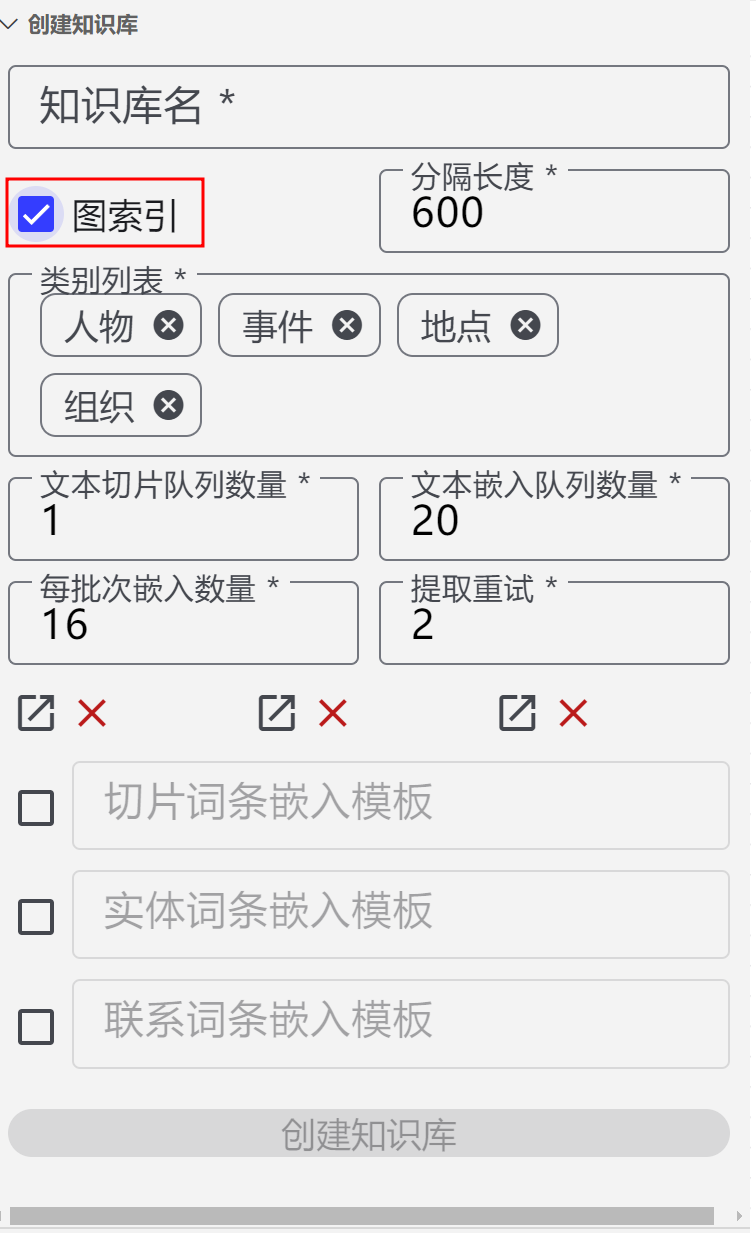
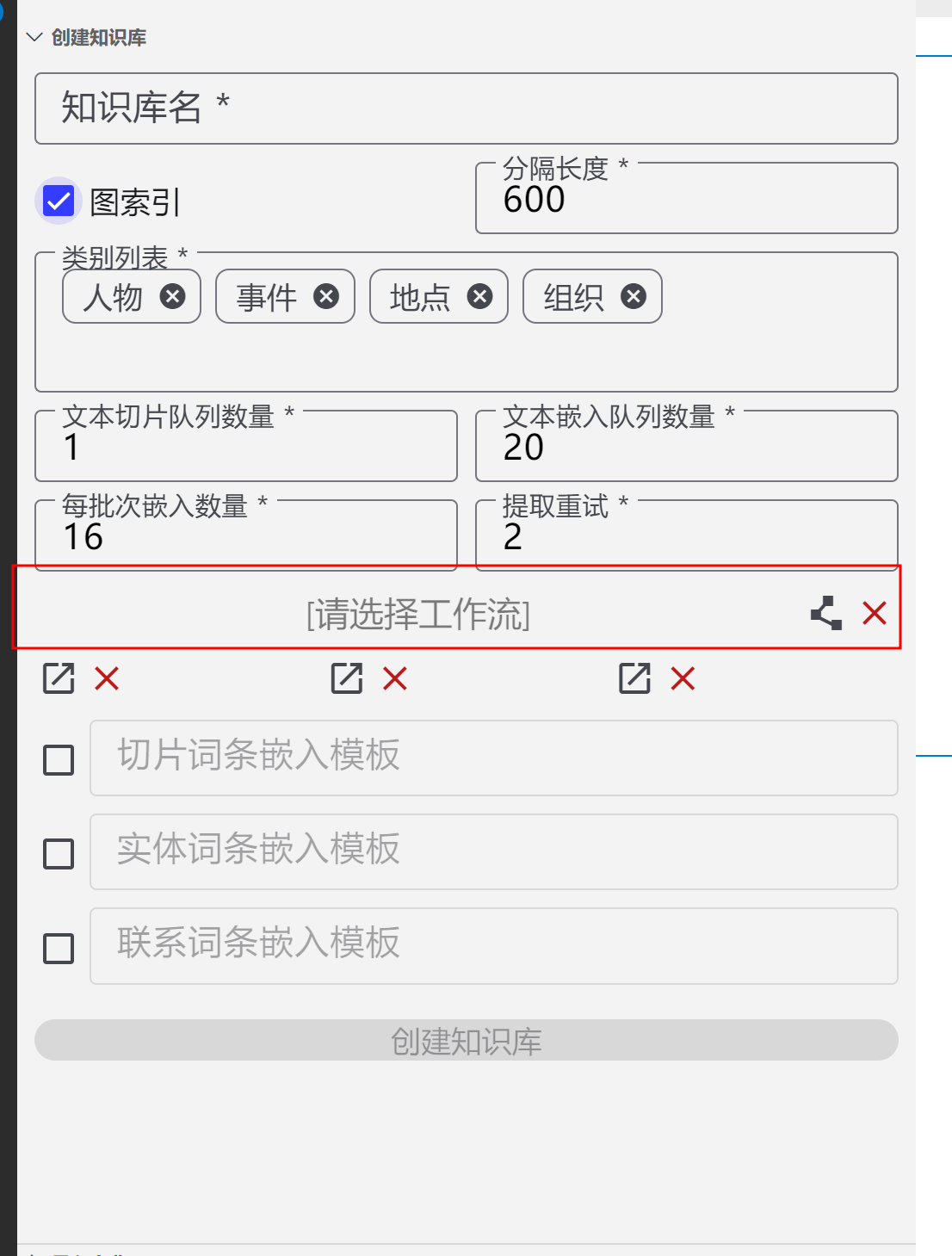
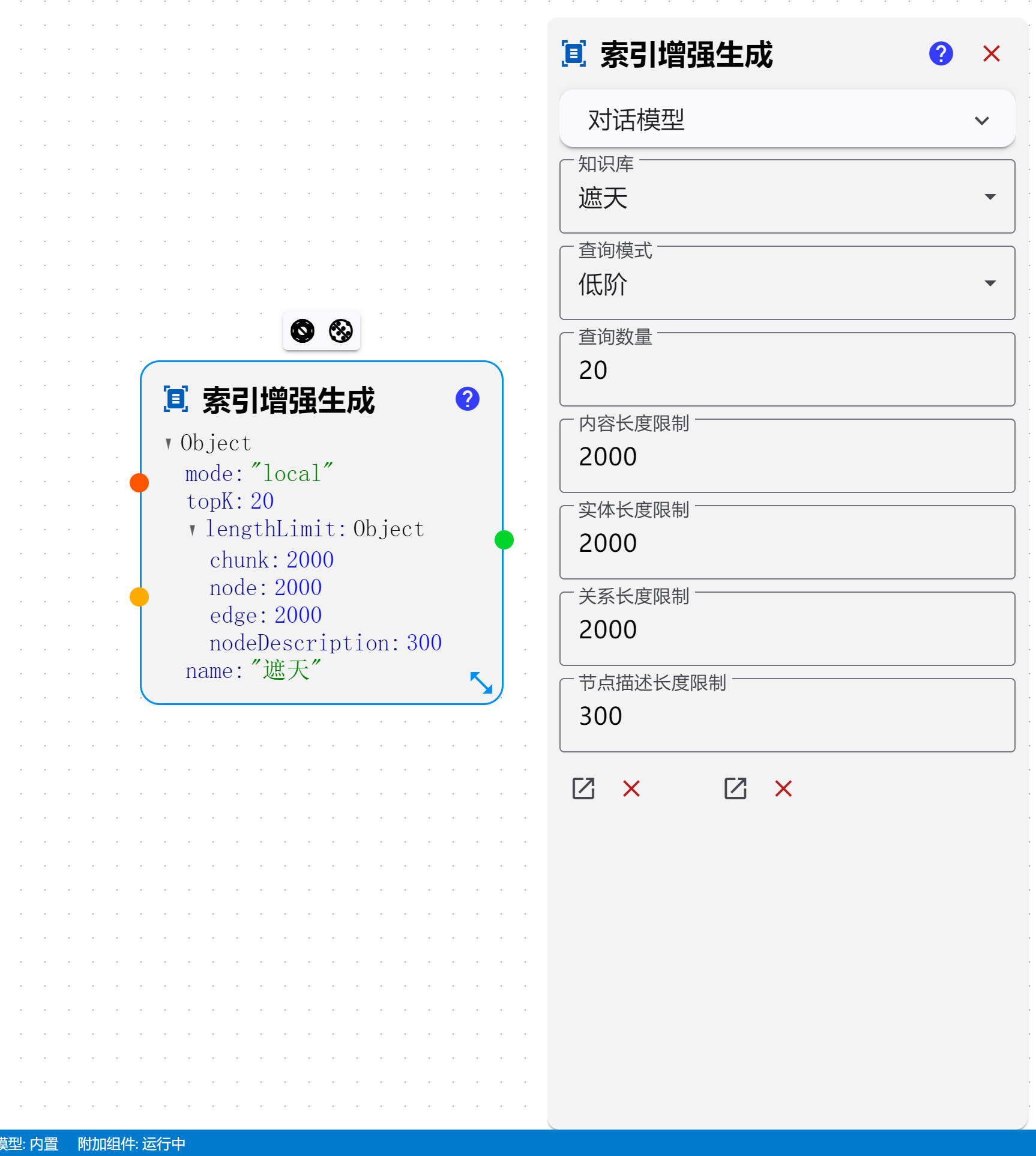
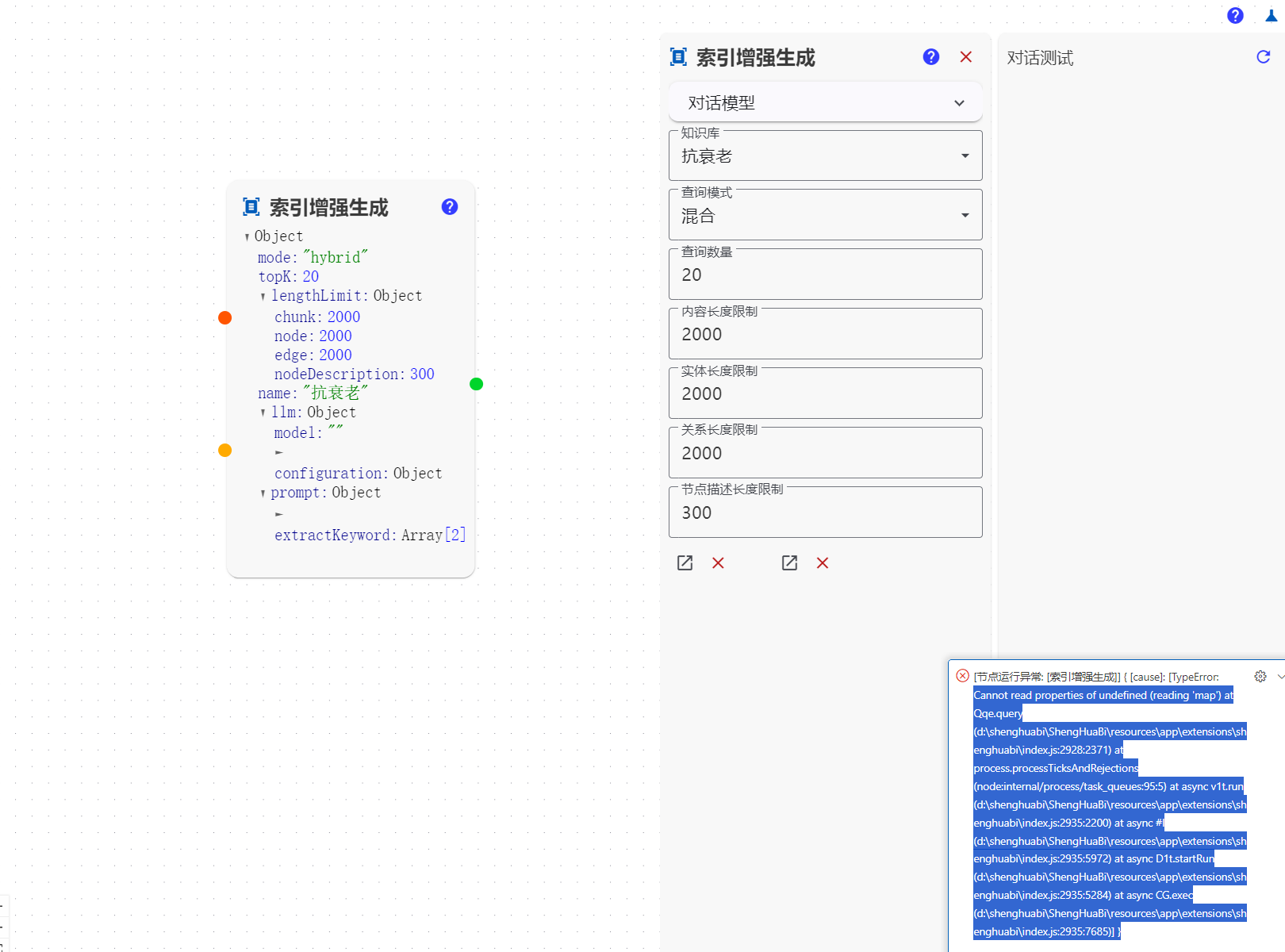
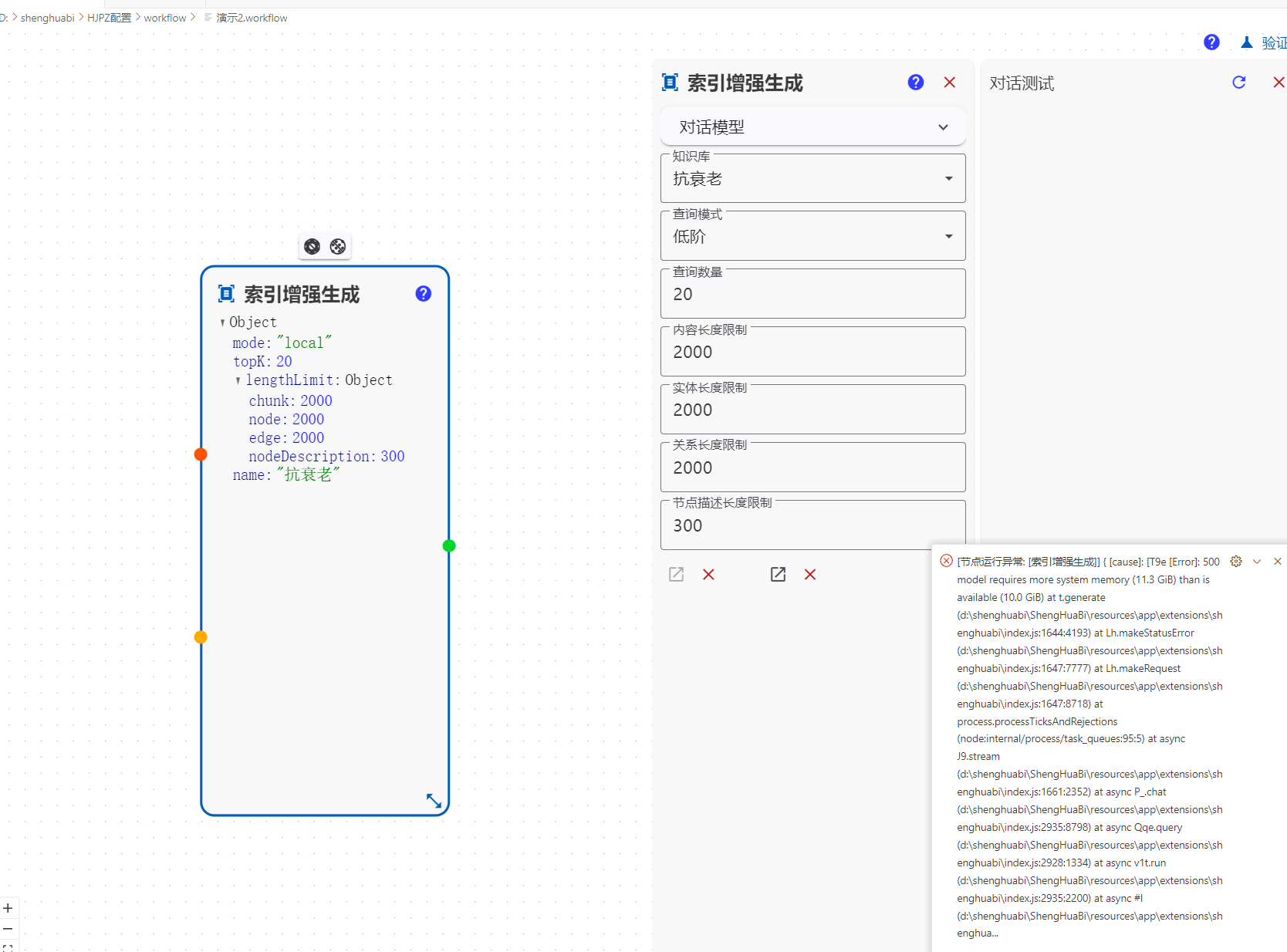
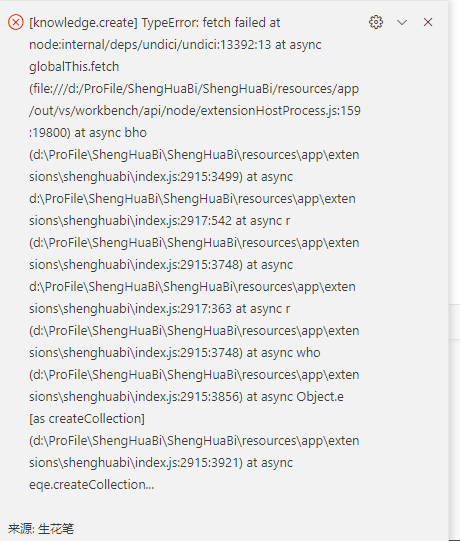
[节点运行异常: [索引增强生成]] { [cause]: [T9e [Error]: 500 model requires more system memory (11.3 GiB) than is available (10.0 GiB) at t.generate (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghuabi\index.js:1644:4193) at Lh.makeStatusError (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghuabi\index.js:1647:7777) at Lh.makeRequest (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghuabi\index.js:1647:8718) at process.processTicksAndRejections (node:internal/process/task_queues:95:5) at async J9.stream (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghuabi\index.js:1661:2352) at async P_.chat (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghuabi\index.js:2935:8798) at async Qqe.query (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghuabi\index.js:2928:1334) at async v1t.run (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghuabi\index.js:2935:2200) at async #l (d:\shenghuabi\ShengHuaBi\resources\app\extensions\shenghua…