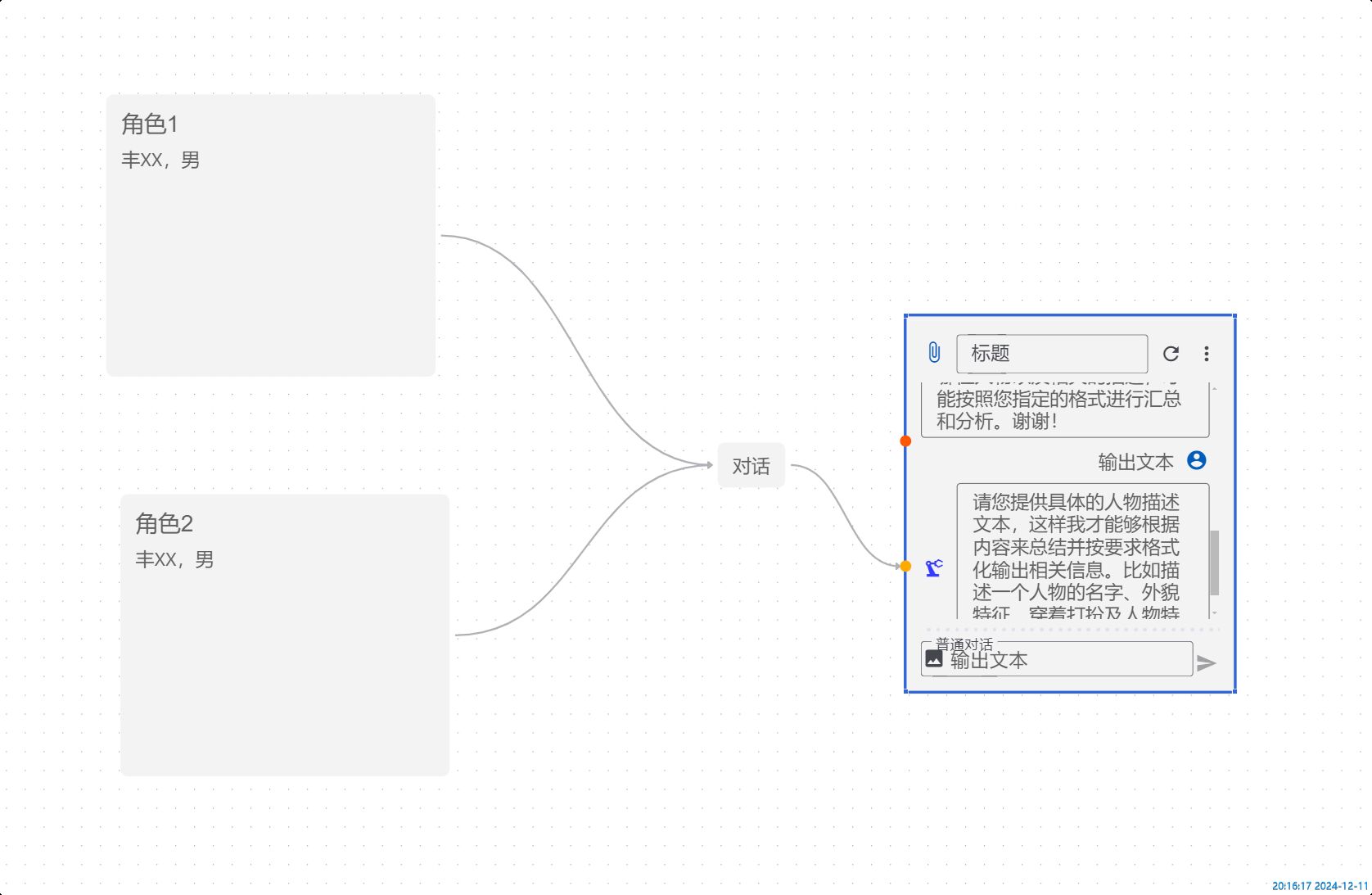
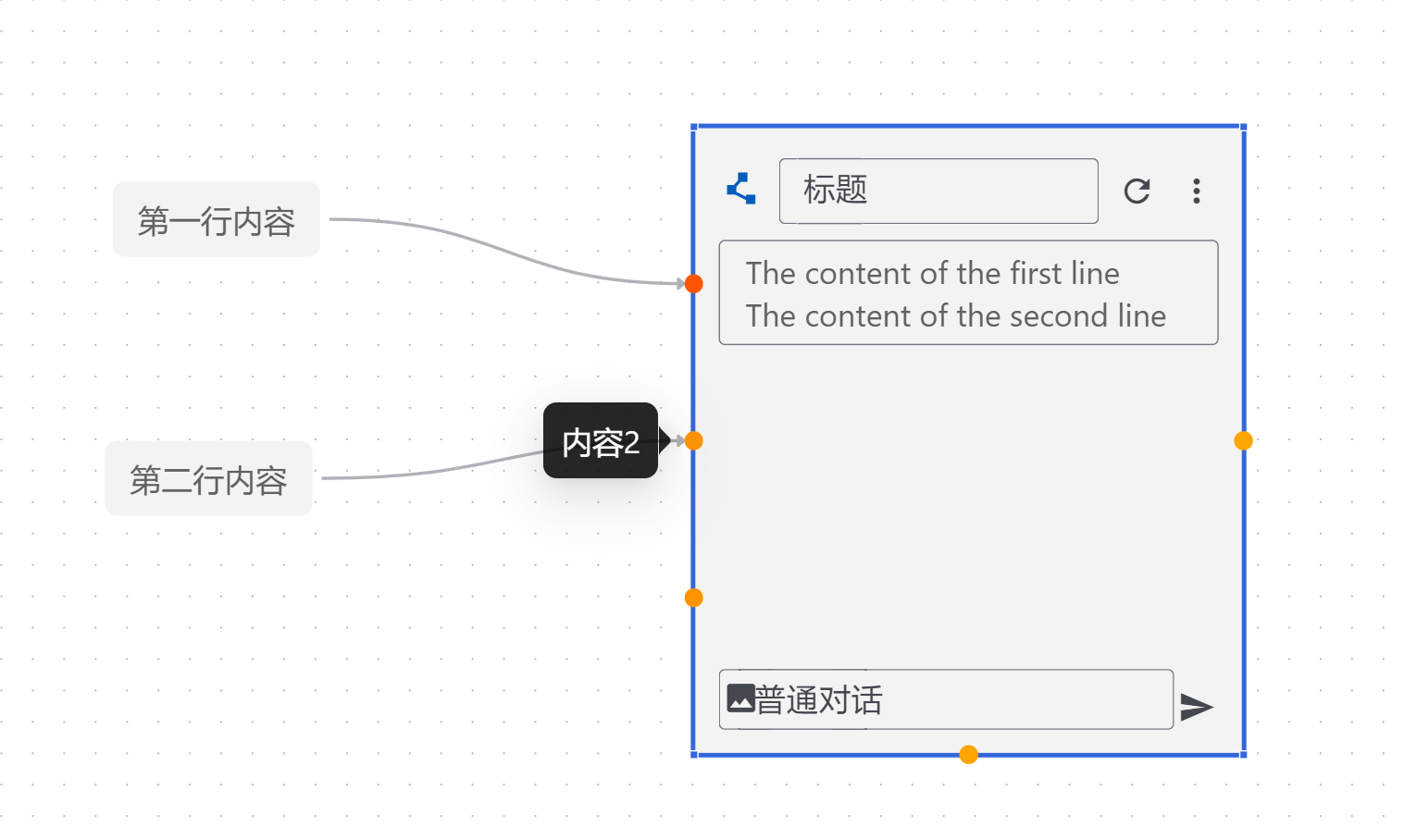
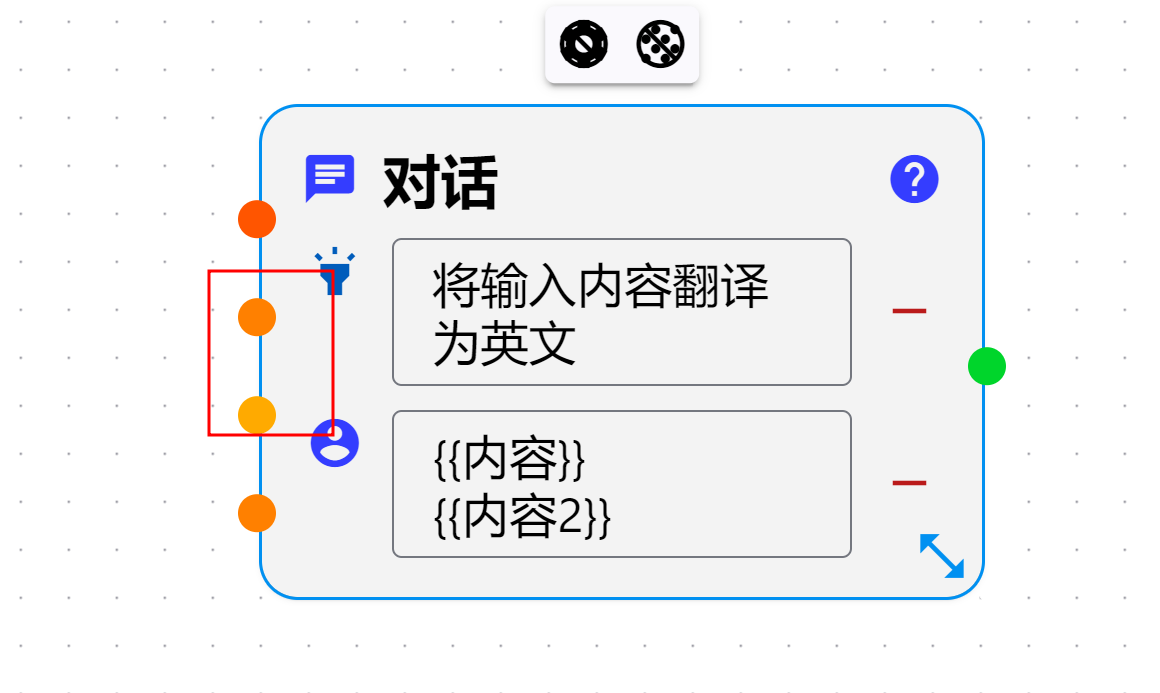
优化知识库及其他工具创建流程
- 我发现很多人卡在这一步,原因就是很多时候没有报错,或者保存无法理解只能我来解决,所以这次我会将一些初始化步骤,每个可能报错的地方都优化一下,方便大家使用
工作流相关
- dify的话研究过,但是没有发现有啥魔法级的东西;目前来说,除了它内置了很多api没法实现(可以搬运,但是搬运后维护也是问题,毕竟移植也需要验证可靠性,光这个工作量就是没法完成的…),其他的我感觉差不多.不知道大家具体需要它的哪个功能,我可以去具体实现
- 准备加个通用api node用来请求接口,虽然说没法实现每一个,但是实现一个通用的还是可以的
- 准备给脚本节点中增加一个创建json schema的方法.ollama 最近支持结构化输出,可以使用json schema规定返回结构.(这个我以前就加过,然后去掉了,原因就是当时的格式是固定的,并且schema不是传入到ollama中而是写在提示词中,所以很难用).
此功能支持后就可以完美的定义返回的数据结构了(虽然说返回结构完美了,但是精度我看其他测试说会稍微下降,毕竟有约束了吗,不像之前自由)
可选
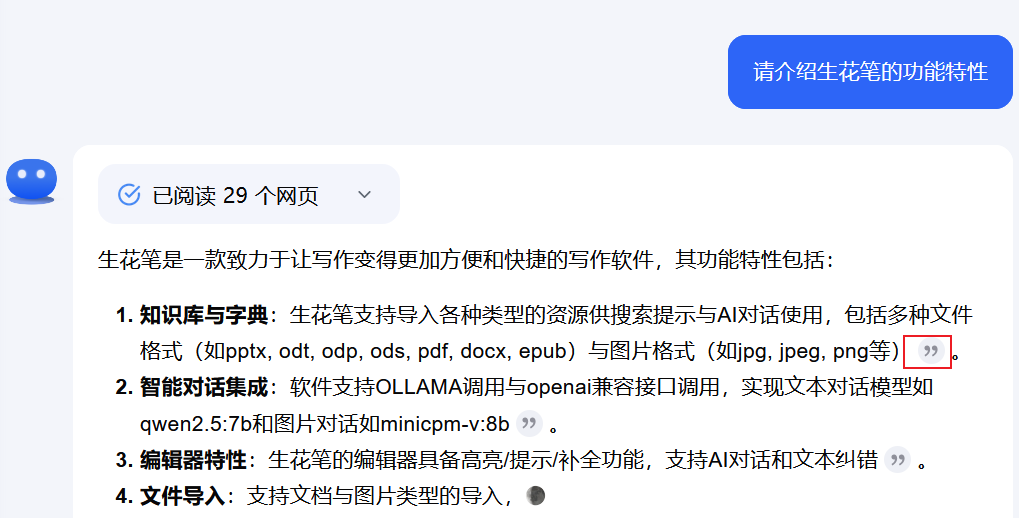
- 文本纠错更新,GitHub - shibing624/pycorrector: pycorrector is a toolkit for text error correction. 文本纠错,实现了Kenlm,T5,MacBERT,ChatGLM3,Qwen2.5等模型应用在纠错场景,开箱即用。 目前支持了qwen2.5的微调模型,并且我目前也找到判断电脑设备的方法,可以加上硬件加速,但是不知道大家对这方面功能是否需要
其他
- 欢迎大家提出宝贵建议(有时候看到大家留言,也想实现,结果写着写着就忘了…所以如果目前还没有明确答复及已经实现的功能可以继续留言
 )
)