测试多对话.exe
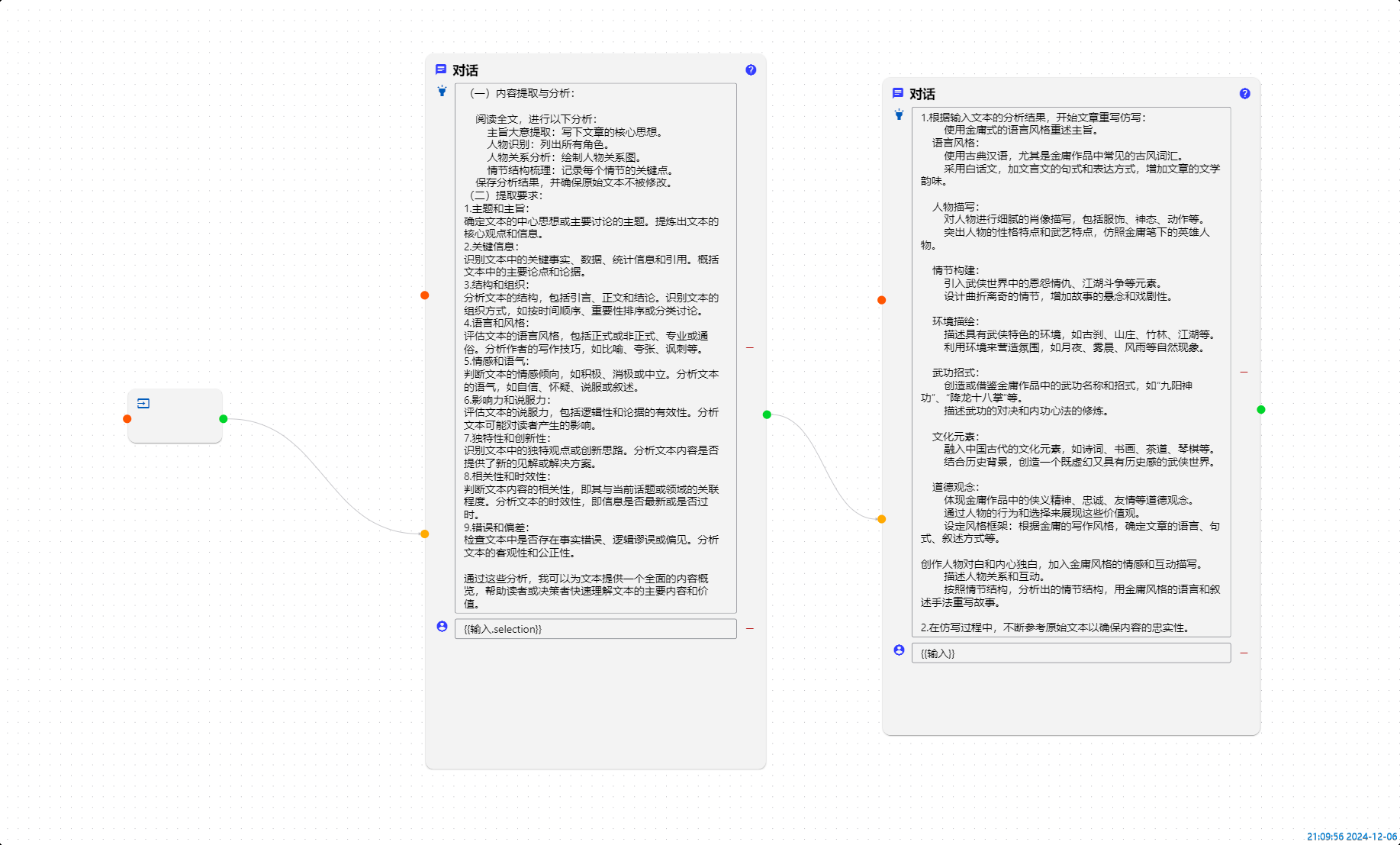
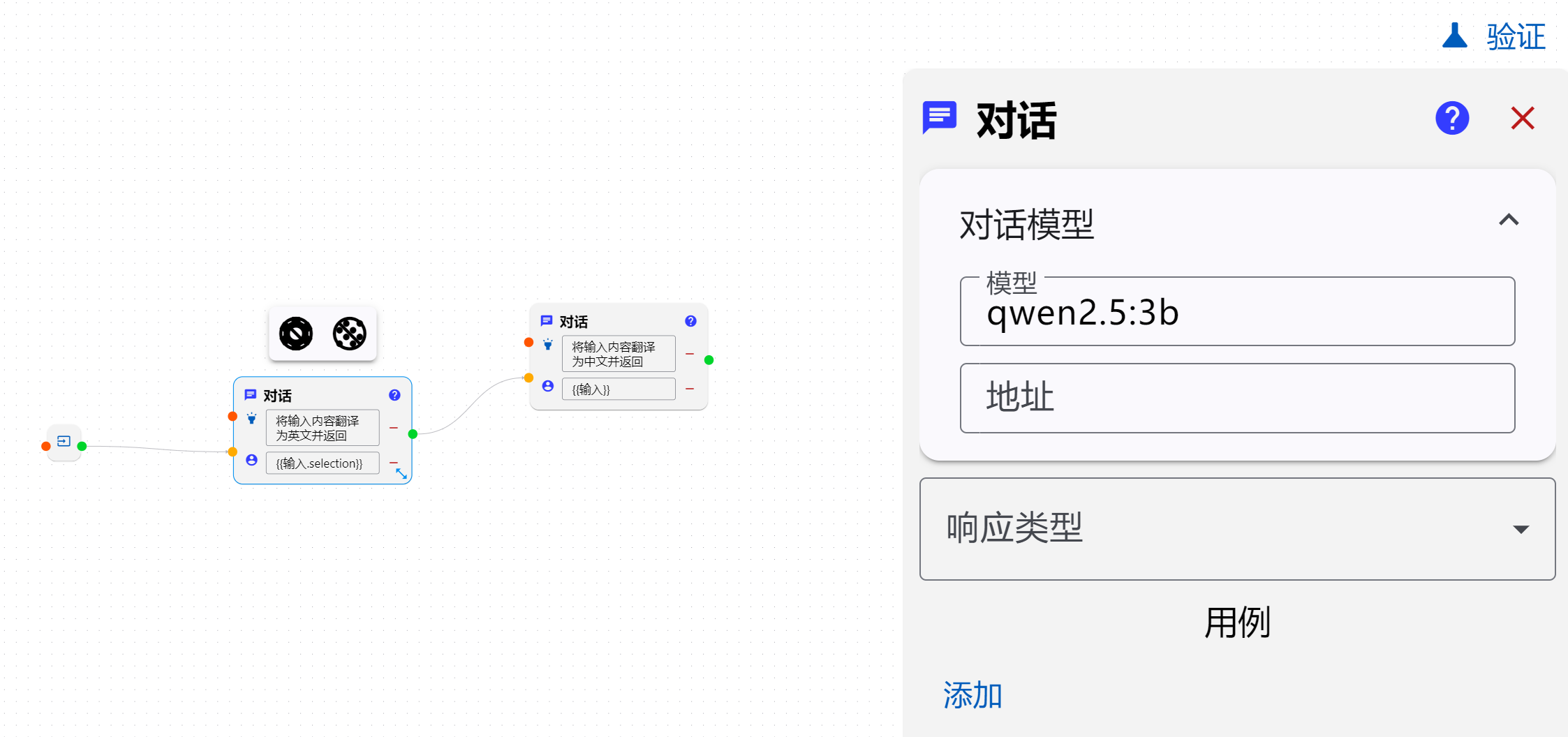
目前来讲一个工作流中有多个对话节点,或者每个节点指定不同的模型都是可以正常运行的,包括编辑器内使用(一点点小的显示问题.)
因为云盘不支持分享exe以外的文件,所以都是自解压格式
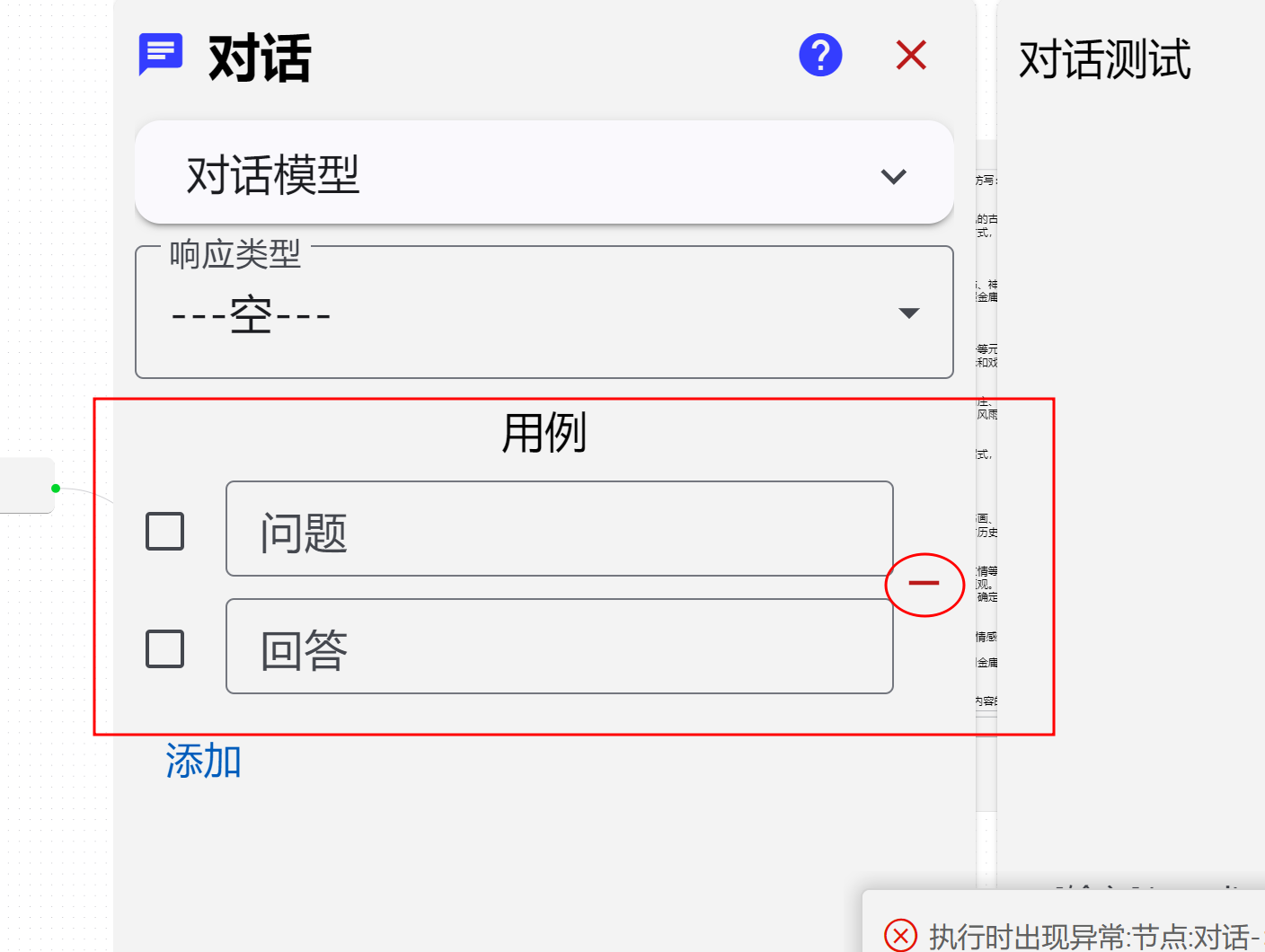
执行时出现异常:节点:对话->节点:对话 {“name”:“ZodError”,“message”:"[\n {\n "code": "invalid_union",\n "unionErrors": [\n {\n "issues": [\n {\n "received": "ai",\n "code": "invalid_enum_value",\n "options": [\n "system"\n ],\n "path": [\n 2,\n 0\n ],\n "message": "Invalid enum value. Expected ‘system’, received ‘ai’"\n },\n {\n "code": "invalid_union",\n "unionErrors": [\n {\n "issues": [\n {\n "code": "invalid_type",\n "expected": "string",\n "received": "undefined",\n "path": [\n 2,\n 1\n ],\n "message": "Required"\n }\n ],\n …
我这个不行,没有指定不同的模型。
共享到网盘上我调试一下看看?
共享啥?exe,我都没改动什么咧》要用你分享的EXE才行?
链接:百度网盘 请输入提取码
提取码:e8pr
复制这段内容后打开百度网盘手机App,操作更方便哦
找到问题所在,尝试解决.抱歉
可以更新1.95.11,会自动过滤掉空的用例,或者手动删除
感谢博主的迅速响应!现在反馈多个对话模型工作流的使用情况。对话模型:qwen2.5-14B
1.多个对话模型根据字数的的增多,响应处理时间随之增加,目前测试50-500字,处理时间会在1分钟-35分钟才能生成。(目前看处理时间与对话模型的数量没有显著相关,)
2.使用多个对话模型工作流生成文本质量,远差于单个对话模型。不管是无限制扩写重写,还是限制式续写仿写,多个对话模型工作流无法根据原始文本生成可用的文本,还不如AI对话功能模块,反复修改对话提示词,效果还是一般。(注:提示词是用各个网页版的AI网站生成的。)
3.目前生花笔软件的工作流跟倾向是和一个智能体对话讨论,无法分解理解任务,复杂的任务理解不了,简单任务又不能准确传递信息文本,把任务目标串联起来。
PS:dify网站的工作流可以调用API,每个节点的提示词都十分简单,可以生成质量不错的文本内容,暂时没有测试API大模型的工作流情况,模型量应该是有很大影响的。
希望能够一起努力,看看小模型实现可用的工作流的可能有多少
其实目前所有的工作其实都是在设计抽象,而不是研究具体提示词,所以如果某个场景(您想做的),无法通过工作流来表示出来,请描述一下,我可以增加对应的设计
目前现阶段的话,我也会看看其他的项目是怎么设计这块的,然后取长补短
不过最好的当然还是用户提出的建议更加贴合实际
没错,提示词是在小模型推理理解能力不足的时候,起到大作用。工作流或许可以参考dify,但是没开源,有点麻烦。工作流后面应当倾向文字创作,如风格仿写、角色卡的长上下文本理解的方向
那么现在有没有在创作时遇到工作流无法实现的功能?或者您觉得dify哪个功能目前现在软件不具备