目前厂商的小模型都集中在编码、数学能力、文本推理生成能力、对话理解能力这几方面,生花笔应当是倾向学习创作方面的,即是文本推理生成、对话理解能力。
目标不需要追求token,那么就是文本细节了,最容易实现的,留得住用户的是AI对话、工作流的模块,虽然没有结合知识库,但是问题不大。
应当从扩写细纲、建立角色卡工作流的方向优化。
可以看一下这个开源项目:GitHub - duoyang666/ai_novel: 实验ai小说
使用视频:来了,完全免费的ai小说写作工具,一个不配收费的软件_哔哩哔哩_bilibili
这个有角色卡,有点意思,不过写作是抽卡式的,应该是对话模型限制了
1 个赞
admin
3
目前准备加一个
这个和左侧的对话其实是一样的(左侧也有直接替换的按钮),但是优点我觉得就是属于编辑内部一体的(vscode内部实现,看起来整洁些)
另外准备添加读取卡片功能供工作流使用,这样的话就可以把卡片中的信息插入到模板更好的实现生成了
说到知识图谱,目前的知识图谱缺少方向性,知识图谱最大的作用就是看到图就能够知道谁影响了谁,整个事件的发生和进行的方向是什么样的,实体和实体之间别用短线链接,需要箭头的指向。第二是实体的颜色最好根据标注的属性,相同属性用同一种颜色区分。还有就是节点图形实在太小了,首先需要有一个位置的聚焦,其次,点直径大小要调整。这就是我目前用了图谱后的想法,供您参考
admin
6
尺寸方面我尽量调整,颜色标注我看看怎么显示最好,因为目前是根据关系远近来的.
连接线其实没啥用…因为我之前也加上了,但是在图谱的规格上来后,就会发现整个屏幕基本上都是灰色的,根本看不到谁是谁 
1 个赞
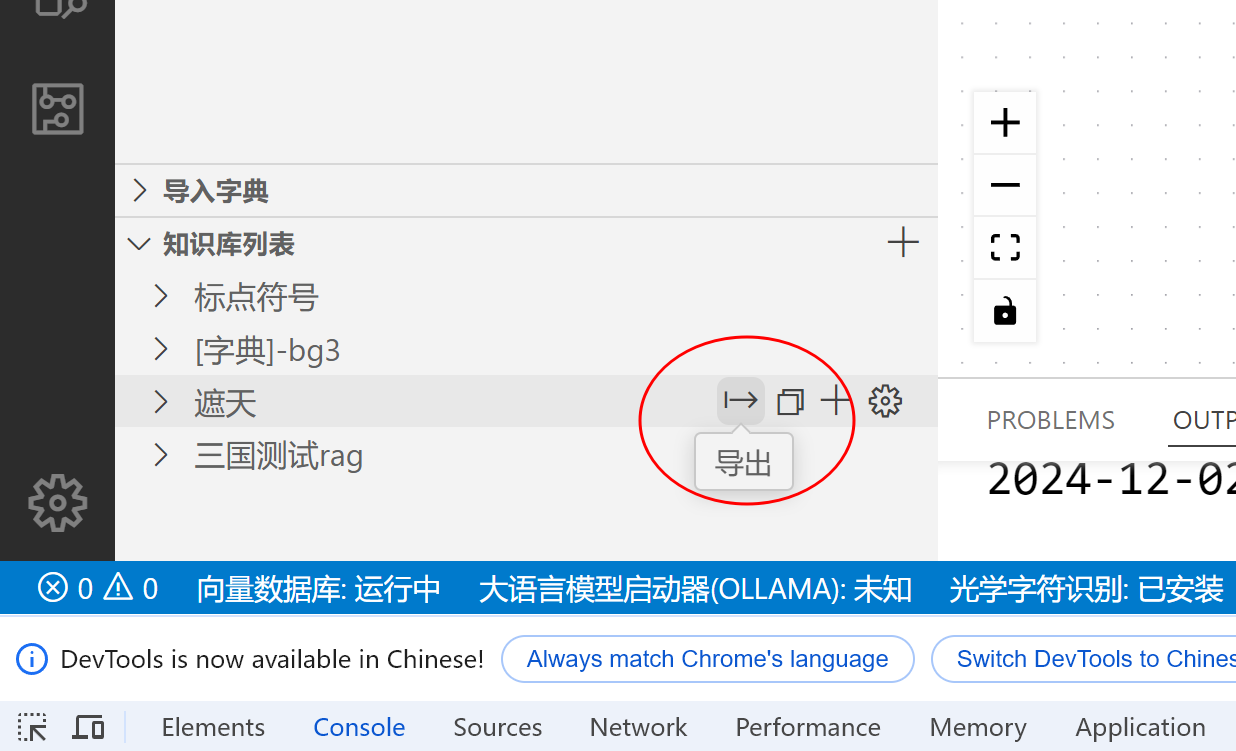
博主,我们做的知识图谱可以导出来吗,一般这个文件一般存在那个文件夹下呀;这个论坛网络链接应该不太稳定,上午一直报错。
不是存放在mind文件夹内吗?知识库每一个书籍右边的导出按钮
admin
10
上午是因为服务器有一点问题,已经联系厂商解决了.不是你的网络或者服务器的网络问题(虽然论坛一直不怎么快)
说起网络刚才我测了下hf-mirror.发现它的服务器竟然变成日本的了,以前我记得是白嫖cf的.ping了一下发现对国内网络来说还行,下个版本改成这个镜像(以前都是我自己搞的白嫖cf的,所以很不稳定.现在它有独立服务器可能比我的方案稳定些)
sishui
13
snapshot.这个比较少,现在jison格式比较主流,方便与各种环境匹配和对接
admin
14
这个是由数据库直接导出的,也就是说可以直接恢复
并且这里面有嵌入的数组,如果说使用json的话,一个文件可能几个g,并且很难找到一个工具进行解析(毕竟json需要从头到尾解析一遍)
当然也可以把数组再单独存…但是折腾了那么半天也没有啥优势,是可以这么做,但是我没有时间这么搞