1.103.40以上
工作流程
解析阶段
- 支持纯文本拆分
- 支持字幕拆分
- 支持工作流自定义拆分
比如使用大语言模型进行拆分并分配
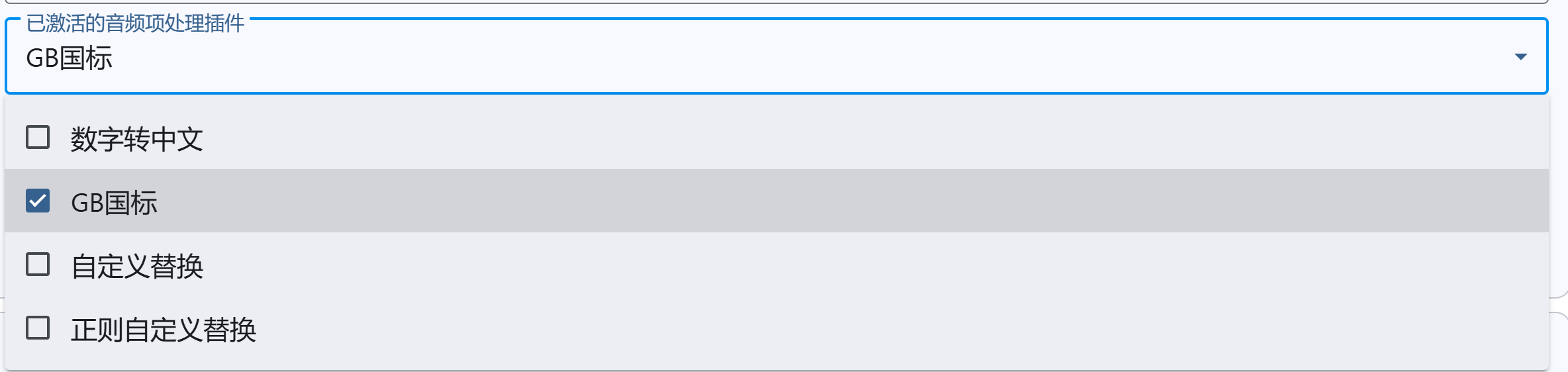
插件预处理项(插件)
- 解析后,会使用激活的音频项插件对每一项进行一个预处理
- 比如希望字幕显示
Intel,但是读英特尔可以在这里实现
本质上就是字幕和音频生成文本是分离的,这样可以最大限度的调整
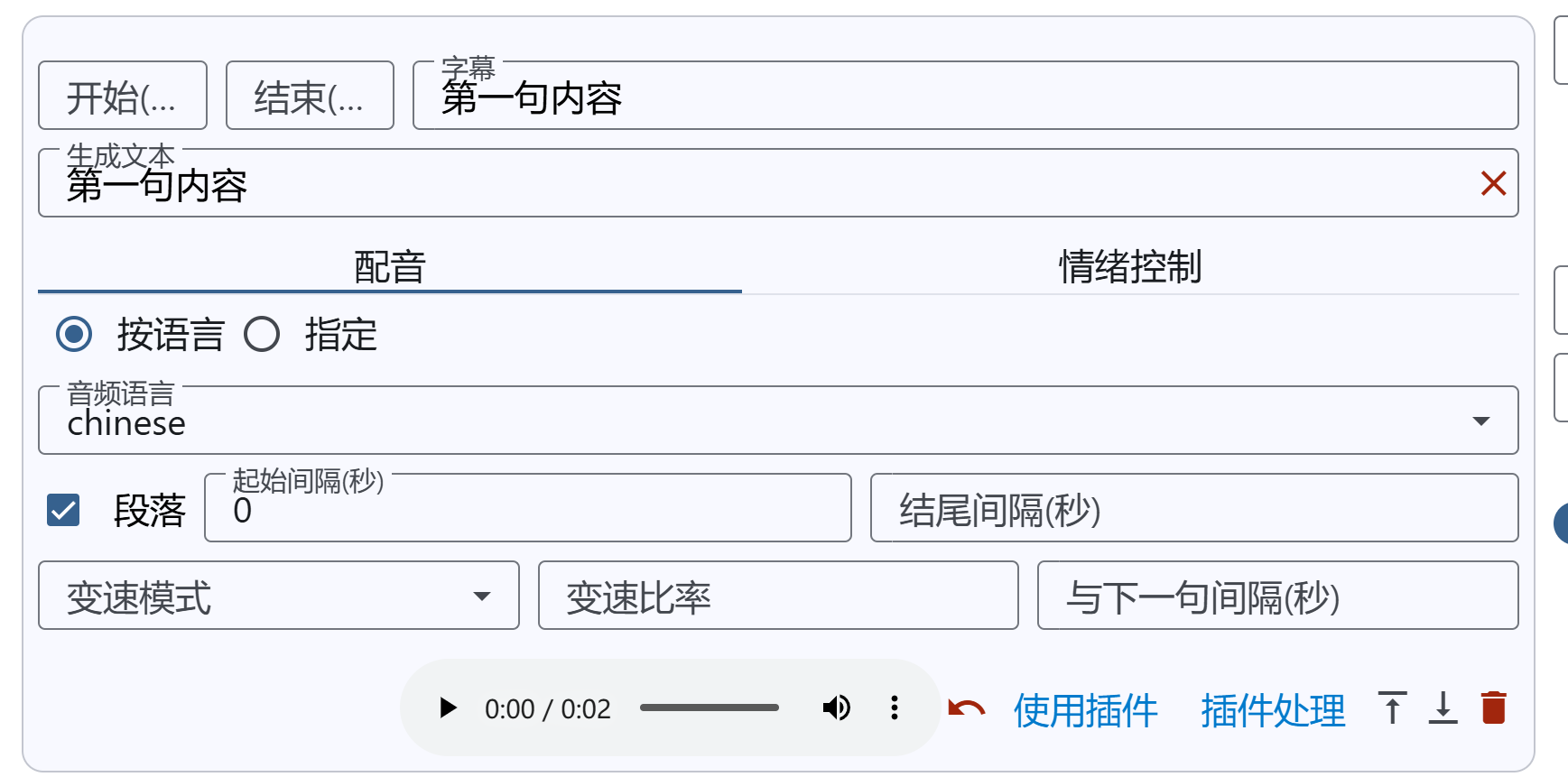
手动调整阶段
- 通过调整页面上的参数,使其复合要求
- 可以使用音频项插件进行再次处理
生成阶段
- 此阶段会调用大语言模型进行文本生成
- 此阶段会生成非常多的音频切片
连接前阶段(插件)
- 模型生成结束后,会产生非常多的音频切片,需要进行连接
- 可以在这个阶段修改
连接配置,改变连接的结果 - 比如我希望对每个音频的前后静音部分进行删除,则可以在这个阶段获得切片路径=>进行处理=>修改切片路径

连接阶段
- 此阶段会使用
连接配置进行音频连接 - 音频连接只做两件事,增加空白音频和字幕对应,设置变速
- 最后生存一个完整的音频文件和字幕文件
连接后阶段(插件)
- 可以修改最后生成的音频文件
- 比如增加背景音乐?
目前提供了接口,没有实例,如果您有什么好的想法欢迎提交
